

La tour mythique de Babel, très souvent, reflète notre propre monde, où tout le monde parle mais personne ne se comprend. Ainsi, bien que l'inspiration de cet article puisse être attribuée à un MYTHE, le sujet de cet article est ancré dans la réalité concrète, à savoir DONNÉES
Alors que la quantité de données qui nous entourent prolifère de manière inimaginable, nous devons faire face à deux problèmes distincts. Le premier consiste bien sûr à utiliser, stocker et protéger ces données à grande échelle et le second à gérer une myriade d'acronymes, un jargon propre à l'industrie, des compréhensions (mal) partagées; tout cela créant une soupe alphabétique de nomenclatures désordonnées.
Cet article vise à démystifier la nomenclature couramment utilisée, et très souvent mal utilisée, lors de l'emploi du terme « DONNÉES » dans le contexte des solutions de sauvegarde, PR (reprise après sinistre), archivage et RC (cyber-résilience).
Il est important de noter que certains de ces termes tendent à être mal utilisés ou mal interprétés pour des raisons historiques, à une époque où ils étaient employés de manière interchangeable. D'autre part, certains termes sont également nouveaux pour l'industrie, et leurs définitions acceptées sont encore en cours d'évolution.
Jetez un coup d’œil à l’image ci-dessous alors que nous plongeons dans certains des termes qui y sont mentionnés.
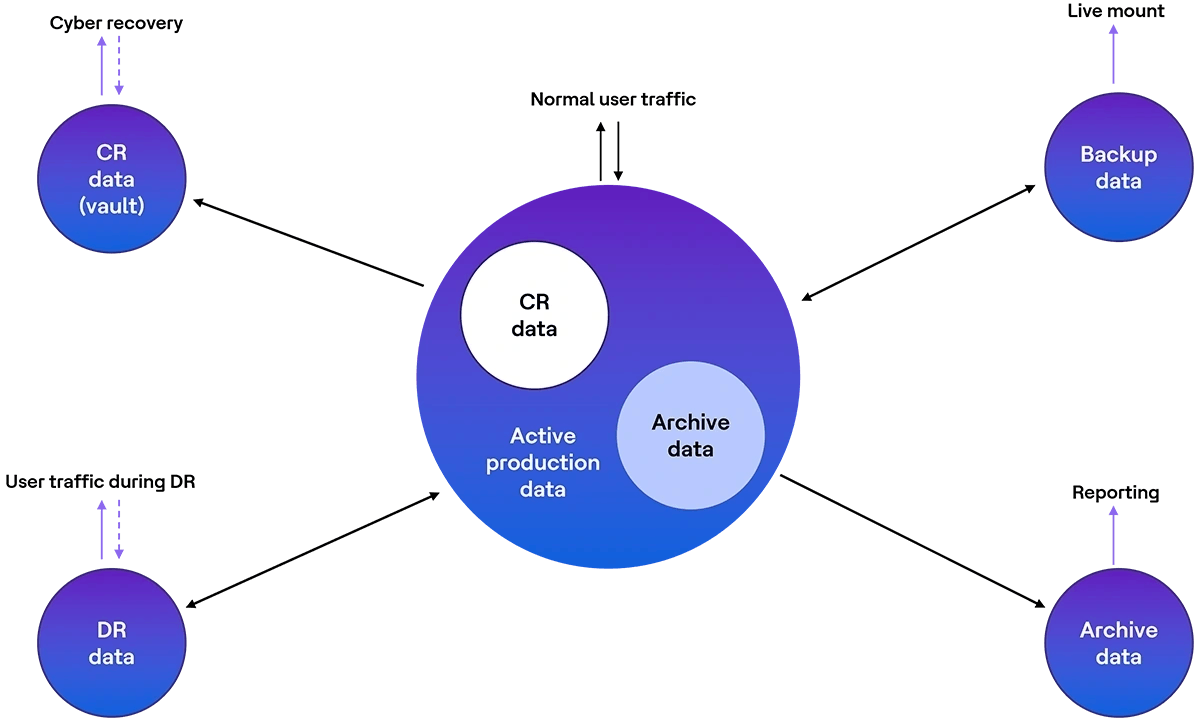
| Données (contenant) | À propos des données (contenant) | |
|---|---|---|
| Données de production actives | Comme son nom l’indique, ces données appartiennent aux systèmes de production qui servent vos utilisateurs durant les opérations normales. Nous ne traçons volontairement aucune frontière entre les données DTA (Développement, Test et Acceptation) et les données de Production, puisqu’à toutes fins utiles, les données DTA servent toujours vos utilisateurs, quoique internes. Comme vous pouvez le voir dans l’image ci-dessus, la flèche bidirectionnelle au-dessus des données de Production indique que ces données peuvent être à la fois consultées et modifiées par les utilisateurs. Les données de production actives seront sauvegardées (complètement ou partiellement selon la politique) et les données de production actives auront également une copie PR (complètement ou partiellement selon la politique) | |
| Données d’archive | Les données d’archive désignent les données qui ne sont plus nécessaires ni pertinentes pour servir les utilisateurs au quotidien. Cependant, ces données restent importantes et pertinentes. Ainsi, ces données sont déplacées hors des données de production actives (contenant) et stockées séparément. Le stockage séparé des données d’archive peut être sous la forme d’une unité de stockage distincte, d’une instance de base de données distincte, d’une instance d’application distincte ou autre. L’avantage de déplacer les données d’archive est que la taille des données de production « actives » est réduite, ce qui peut alors permettre de réduire les coûts de stockage, alléger les besoins envers la solution de sauvegarde et améliorer la performance des applications/requêtes, afin d’enrichir l’expérience utilisateur. L’exemple suivant peut aider à clarifier le concept. Imaginez que vous disposez d’un système de gestion des fournisseurs qui stocke les données de tous vos fournisseurs, leurs commandes, leurs paiements, etc., depuis 1990. Vous pouvez déplacer les données de 1990 à 2000 dans un stockage, une base de données ou une instance d’application séparée, puisque ces données ne sont plus utilisées activement mais doivent être conservées. Cela représente vos « données d’archive ». Ces données peuvent être utilisées à des fins de rapports, mais ne peuvent pas être modifiées de l’extérieur (remarquez la flèche unidirectionnelle au-dessus des données d’archive dans l’image ci-dessus). L’exemple utilise la dimension « temps » pour identifier les données archivables. Mais toute autre dimension comme la géographie, le nom de l’entité, etc., pourrait être utilisée. N’oubliez pas que les données d’archive sont généralement non sauvegardées car aucune nouvelle donnée incrémentielle n’est générée dans l’archive. De plus, les données d’archive n’ont pas de PR, bien que vous puissiez conserver des copies supplémentaires pour plus de protection. | |
| Données PR | Comme son nom l’indique, les données PR sont une copie de vos données de production actives (totales ou partielles) stockées dans un emplacement distinct, vous permettant de remettre vos activités en ligne au cas où les données de production deviendraient indisponibles, c’est-à-dire si le site principal devient indisponible. Les données PR n’ont pas besoin d’être exactement de la même taille que les données de production, car vous pouvez choisir de ne répliquer qu’une partie des données de production. Le transfert (réplication) des données de Production vers le site PR peut se faire de différentes manières, dont, mais sans s’y limiter, la réplication au niveau du stockage ou la réplication de la base de données. Lors d’un scénario de basculement, le trafic utilisateur est redirigé vers le site PR (remarquez la flèche bidirectionnelle pour le trafic utilisateur PR). Après le retour (i.e. quand le site principal est à nouveau disponible), la (nouvelle) donnée est répliquée vers la Production (remarquez la flèche bidirectionnelle entre la production et les données PR) Il est important de noter que les données PR visent à permettre la reprise d’activité après un sinistre classique de site. Les données PR ne sont pas prévues pour restaurer votre entreprise après un événement cybercomme une attaque par rançongiciel. C’est là que les données RC (cyber-résilience) interviennent. Il peut y avoir d’autres nuances quant à la manière dont la PR est mise en œuvre, notamment PR bidirectionnelle ou tridirectionnelle, réplication synchrone ou asynchrone, RTO/RPO différenciés selon les applications, usage de la PR pour le reporting, configuration active/active ou active/passive, entre autres. | |
| Données RC | Le terme RC a de nombreuses acceptions en évolution. Mais au fond, les données RC font surtout référence aux données des « joyaux de la couronne », autrement dit – vos données les plus critiques. Les deux caractéristiques les plus importantes, entre autres, que le « coffre » de RC doit offrir sont « l’isolation » et « l’immutabilité ». Remarquez dans l’image ci-dessus que la flèche des données de production actives vers les données RC est unidirectionnelle. L’objectif ultime de ces données RC est de permettre une récupération en environnement stérile ou une récupération cyber complète, selon les ressources disponibles. Les données RC ne sont pas destinées à être utilisées à d’autres fins comme le reporting en temps normal. Vous pouvez choisir de conserver plus d’une copie des données RC, même si ce n’est pas la pratique habituelle. Enfin, dans un monde idéal aux ressources illimitées, les données RC pourraient être utilisées pour remettre l’entreprise en ligne et pourraient donc avoir de nouvelles données incrémentielles. Dans ce cas, il faudrait alors une sauvegarde et une PR pour les données RC. Cependant, dans la pratique, de tels environnements sont rares (voir la flèche pointillée au-dessus des données RC) Il existe d’autres nuances ici quant à la manière dont l’isolation peut être assurée, ce qui qualifie de « isolé », ou la différence entre isolation logique et physique. Un autre aspect en évolution est la définition d’un C-RPO/C-RTO (point de reprise/temps de reprise en mode cyber) spécifiquement pour les scénarios cyber, distinct du RPO/RTO classique lié aux sinistres de site. | |
| Données de sauvegarde | Les données de sauvegarde doivent toujours être envisagées dans le contexte de deux activités : sauvegarde et restauration. Les données peuvent être sauvegardées de multiples façons, dont, sans s’y limiter, via des logiciels de sauvegarde ou des fonctions natives de sauvegarde de base de données. Avec les progrès réalisés au fil des ans, il est désormais possible d’utiliser les données de sauvegarde à d’autres fins. Par exemple, avec le montage à chaud, les données de sauvegarde peuvent servir à mettre des machines virtuelles en ligne pour des tests ou la récupération de données. Remarquez la flèche unidirectionnelle menant du montage à chaud aux données de sauvegarde. Les VM montées de cette façon ne sont pas destinées à être utilisées par les utilisateurs et n’ont donc pas de nouvelles données incrémentielles. Il est important de distinguer entre données de sauvegarde et données PR ainsi que données de sauvegarde et données d’archive. Alors que les données PR visent à être le plus proche possible des données de production, à un instant donné; les données de sauvegarde visent à constituer un journal historique de tous les changements subis par les données de production. Ainsi, si la PR a pour vocation de permettre la reprise d’activité lorsque le site principal tombe en panne, l’objectif des données de sauvegarde est de permettre de revenir à un état précis dans l’historique. À l’inverse, la mise en place d’une solution PR ne retire pas le besoin d’une sauvegarde. Les données de sauvegarde seront toujours nécessaires pour revenir à un état précis dans l’historique. En fait, dans la plupart des cas, une copie des données de sauvegarde est aussi conservée sur le site PR, permettant au site PR de revenir à un état donné dans l’historique. Dans de nombreux cas, le terme « données de sauvegarde » est aussi employé de façon interchangeable avec archive. Comme expliqué précédemment, le terme données d’archive indique que ces données ne sont plus actives et donc non sauvegardées. Toutefois, puisque la sauvegarde vous permet de revenir à un état donné dans l’histoire, elle peut, parfois, répondre à vos besoins d’archivage (le terme « archivage » prend alors un sens restreint). | |
En résumé, lorsque vous examinez votre environnement, les différents types de contenants de données expliqués ci-dessus représentent différents cas d’utilisation ou besoins, mais ils représentent aussi des coûts et une complexité de gestion supplémentaires.
Il est donc fortement recommandé, pour chaque contenant de données –
- Déterminez quelles données chaque contenant doit inclure; tous les contenants n’ont pas à comprendre toutes les données
- Définissez l’usage de chaque type de données. Chaque contenant doit remplir un besoin spécifique
- Précisez les besoins technologiques de chaque contenant, dont le type de stockage, le nombre de copies, etc. Ceux-ci seront propres à chaque contenant.
Pour en savoir plus, vous pouvez nous écrire à HCBU-PMG@hcltech.com.
