

Les grands modèles de langage (LLM) ont été entraînés sur un vaste corpus de données au fil du temps en utilisant d’importantes ressources de calcul. Ces modèles fondamentaux présentent des propriétés émergentes qui vont au-delà du simple langage, permettant aux chercheurs de tirer parti de leurs capacités pour décomposer des tâches complexes, raisonner et résoudre des problèmes. L’interaction avec les modèles de langage diffère des paradigmes d’apprentissage automatique et de programmation où le code informatique est écrit avec une syntaxe formalisée pour interagir avec des bibliothèques et des API. À l’inverse, les LLM interprètent le langage naturel ou les instructions rédigées par l’humain et exécutent des tâches de façon similaire au comportement humain. L’entrée fournie à un LLM est appelée une invite.
L’objectif de ce blogue est de comprendre comment rédiger, affiner et optimiser des invites en langage naturel pour atteindre le but recherché. Nous allons présenter le LLM, explorer les meilleures pratiques et principes pour créer des invites efficaces et discuter de l’optimisation des performances d’un modèle et de l’atténuation de ses limitations à l’aide d’invites.
Qu’est-ce qu’un LLM?
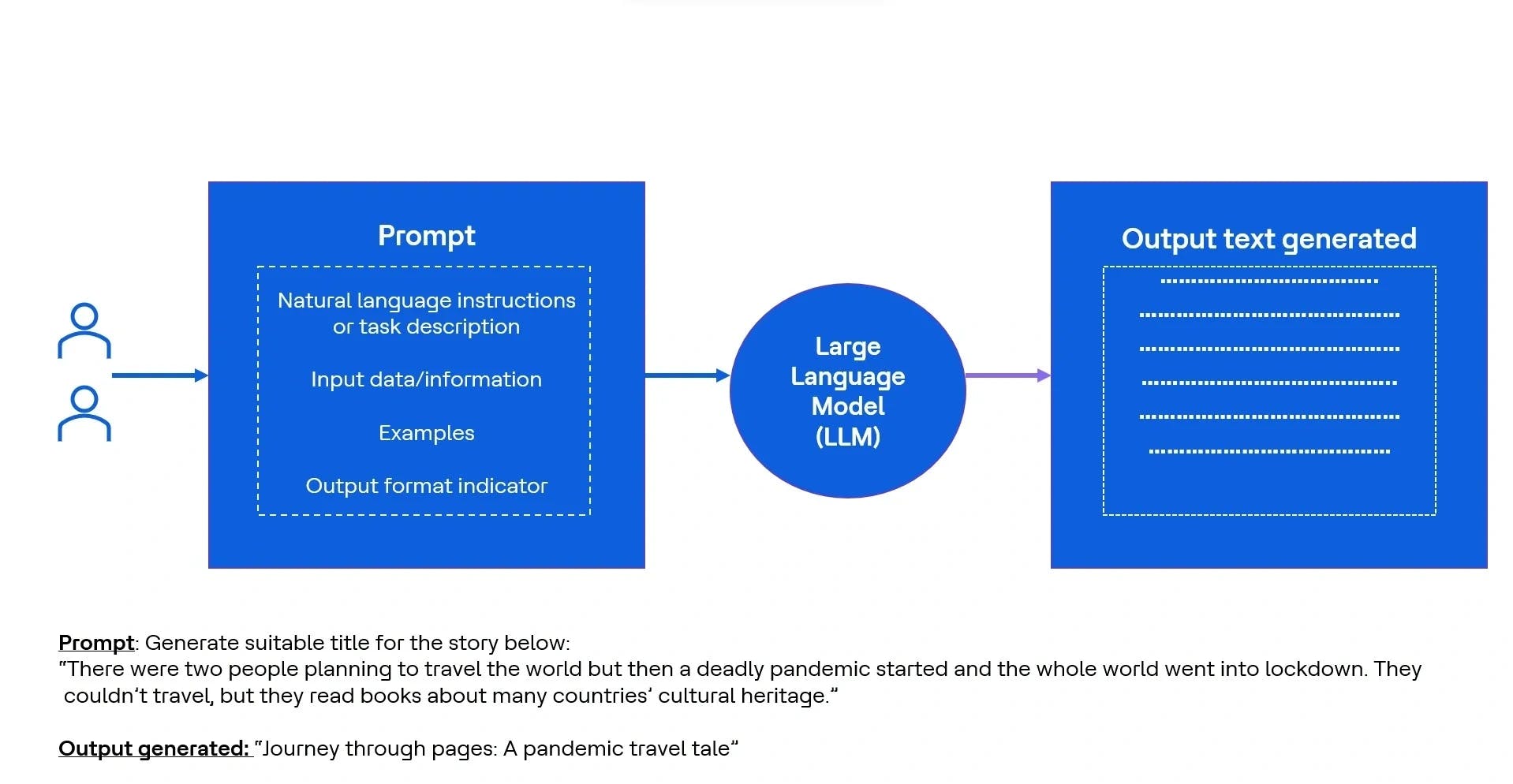
Figure 1 LLM
Un LLM est un modèle d’apprentissage profond capable de générer un texte semblable à celui produit par un humain. Il est entraîné sur d’immenses quantités de données issues de livres, d’articles, de sites web, de documents, et plus encore. Par leur exposition à des ressources de langage naturel, ces modèles développent une compréhension approfondie du langage humain, à la manière d’experts de la langue en ce qui concerne la grammaire, la structure des phrases et l’art de la conversation.
Puisque les LLM sont entraînés sur un vaste corpus de textes, ils peuvent générer des réponses naturelles à une grande variété de requêtes ou d’invites. Ces modèles possèdent une capacité intrinsèque à saisir le contexte et à générer un texte cohérent à partir de l’entrée reçue. Leurs capacités, combinées à leur taille impressionnante et à une vaste base de données d’entraînement, font des LLM une technologie passionnante au potentiel transformateur.
Ingénierie d’invite et invites
Les invites sont des instructions construites stratégiquement en langage naturel pour guider le LLM vers certains objectifs.
L’ingénierie d’invite, un domaine relevant de l’IA et de l’AA, consiste à développer et améliorer les invites pour assurer la qualité des réponses et réduire la latence de génération de texte du LLM. Les invites jouent un rôle déterminant pour donner la direction, le ton et la portée de la réponse générée. Grâce à l’ingénierie d’invite, les spécialistes en IA conçoivent soigneusement des invites pour atteindre des objectifs précis.
Créer une invite utile est un processus itératif qui nécessite souvent plusieurs révisions du langage afin d’aligner le comportement du modèle sur le résultat souhaité.
Cas d’utilisation des invites
Le langage naturel est complexe et puissant. Lorsqu’il est utilisé pour instruire les modèles de langage à effectuer une tâche, les cas d’usage deviennent illimités. Par exemple :
| Tâche | Explication |
|---|---|
| Résumé |
|
| Inférence |
|
| Transformation |
|
| Développement |
|
Points à retenir pour rédiger de bonnes invites

Figure 2 Bonnes pratiques pour rédiger une bonne invite
Une invite bien conçue sert de contexte et de cadre directeur pour que le modèle atteigne le résultat attendu. Structurer et formuler efficacement les invites est essentiel pour optimiser la performance des LLM et obtenir les réponses recherchées. Contrairement à la croyance populaire, rédiger une invite requiert une compréhension nuancée de la langue et de ses usages contextuels variés. Une invite bien construite repose sur de nombreux facteurs, notamment :
- Clarté et pertinence : L’ambiguïté du langage est un défi commun et des invites précises permettent d’éviter les interprétations erronées, conduisant à des réponses plus pertinentes et précises.
- Adaptation du style et du ton : Intégrer des références pertinentes ou des instructions claires quant au style d’écriture souhaité dans les invites permet aux LLM de générer des résultats qui correspondent aux attentes de l’utilisateur. Par exemple, en spécifiant le nombre de mots ou de phrases, le format ou le public cible (demander des informations sur la lune à un enfant de 5 ans versus à des scientifiques).
- Portée limitée : Définir la portée de l’invite pour éviter les sorties hors sujet ou non pertinentes.
- Diversité : Fournir un large éventail d’exemples dans les invites aide le LLM à comprendre le contexte et à généraliser les concepts.
- Contrôle de la qualité des résultats : L’ajout d’instructions visant la vérification des faits ou des contraintes dans les invites facilite la validation de l’information et la production de résultats fiables.
- Réduction des biais : Les LLM étant principalement entraînés sur des données tirées d’internet — qui contiennent des biais, de la désinformation et du contenu non éthique — cela demeure préoccupant. Les invites peuvent jouer un rôle clé pour orienter les LLMs à réduire l’effet des biais et favoriser des résultats objectifs et équitables.
- Optimisation et efficacité : Les LLM sont des modèles puissants qui requièrent d’importantes ressources informatiques et du temps pour générer des résultats. Concevoir des invites bien structurées aide à optimiser la performance et l’efficacité de ces modèles. Les invites bien élaborées fournissent suffisamment de contexte tout en limitant l’apport inutile, permettant ainsi aux LLM de produire des réponses de façon plus efficace et rapide. Cette optimisation améliore l’expérience utilisateur globale et accroît l’utilité pratique des LLM.
Maintenant que vous connaissez les LLM, l’ingénierie d’invite et les invites, ainsi que l’importance de leur conception soignée, examinons les grands principes et tactiques pour devenir un rédacteur d’invites efficace.
Principes de l’ingénierie d’invite
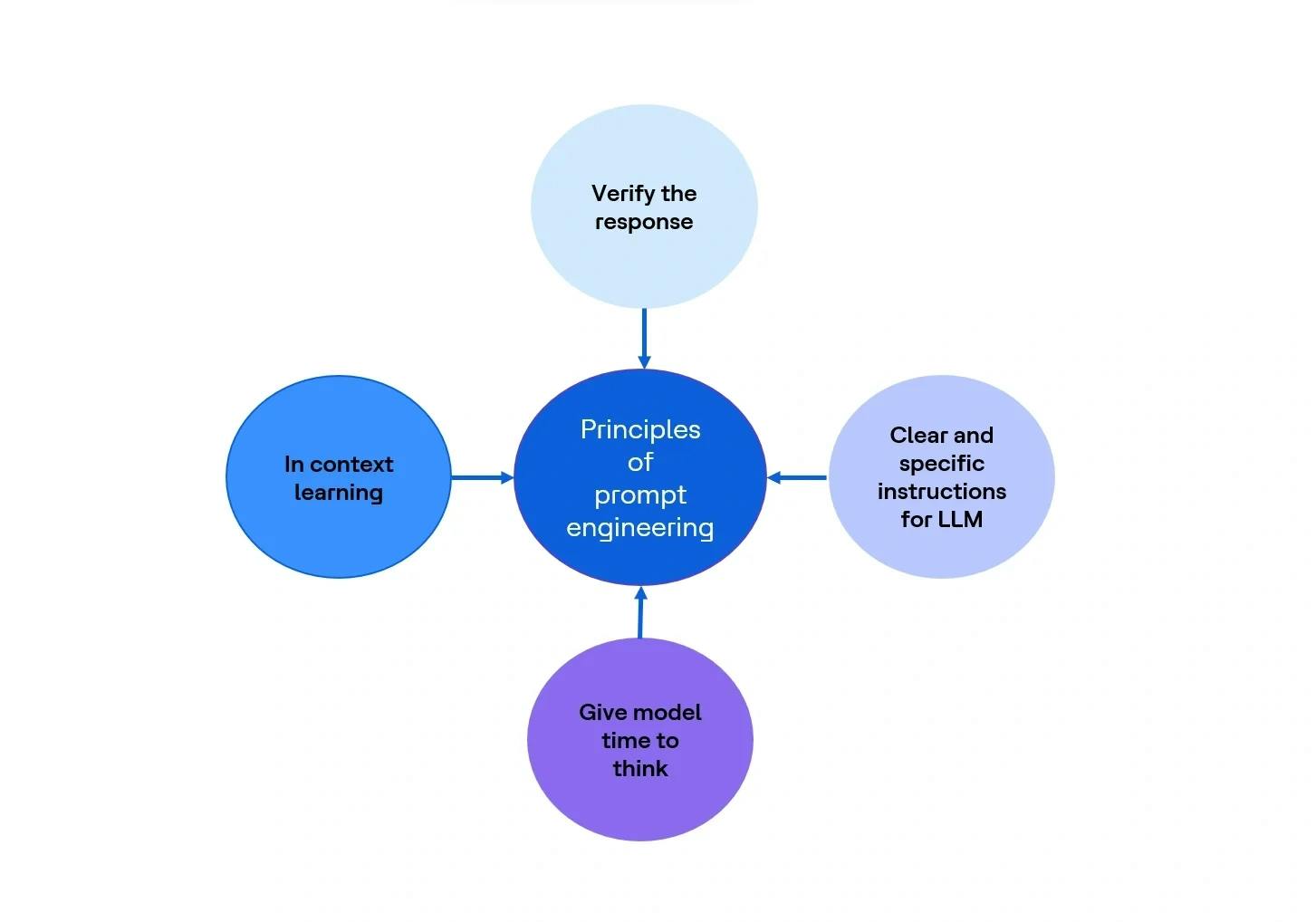
Figure 3 Principes de l’ingénierie d’invite
Instructions claires et précises pour le LLM
Des instructions claires et précises servent d’outils directeurs pour amener le modèle vers la bonne réponse. Il n’est pas nécessaire de concevoir des instructions extrêmement précises mais elles doivent contenir toutes les informations essentielles pour donner le contexte au LLM afin de générer une réponse pertinente et recherchée.
- Utiliser des délimiteurs ou des signes de ponctuation pour séparer les différentes parties des entrées. Cela aide le modèle à distinguer le texte sur lequel il doit travailler de l’instruction fournie par l’utilisateur.
- Demandez une sortie structurée, par exemple en format JSON, HTML ou liste, afin qu’elle puisse être utilisée directement là où c’est nécessaire.
- Vérifier certaines conditions avant de générer une réponse, si requis.
Laisser le modèle réfléchir
Pour réduire le risque d’obtenir des réponses incorrectes des LLM, les utilisateurs devraient prendre en compte certains points lors de la formulation d’instructions afin de fournir suffisamment de contexte et de raisonnement au modèle avant la production d'une réponse.
- Les LLM doivent compléter des étapes pour réaliser une tâche. Il ne doit pas y avoir de suppositions.
- L’utilisateur peut demander au modèle de s’assurer que sa réponse est exacte avant d’arriver à une conclusion.
- Demandez au modèle d’agir dans une capacité spécifique. Par exemple, « agir comme analyste de données et lire le graphique » ou « agir comme un élève de 5e année et lire le graphique ».
Apprentissage en contexte
L’apprentissage en contexte est le processus qui consiste à fournir des exemples avec raisonnement sur le résultat attendu. Grâce à cette approche, les utilisateurs peuvent aider le LLM à mieux comprendre la tâche demandée en incluant des exemples ou des données supplémentaires dans l’invite.
- Inférence à zéro exemple : Lorsque qu’aucune donnée d’entrée n’est incluse dans l’invite
- Inférence à un seul exemple : L’intégration d’un exemple unique
- Inférence à peu d’exemples : Parfois, un seul exemple n’est pas suffisant pour que le modèle comprenne exactement ce que l’utilisateur attend ; dans ce cas, plusieurs exemples peuvent être fournis
- Si le modèle ne donne pas de bons résultats même après cinq ou six exemples, il est conseillé de l’ajuster, c’est-à-dire de lui fournir un entraînement supplémentaire avec de nouvelles données pour le rendre plus apte à la tâche ciblée
Vérifier la réponse
Puisque le modèle est entraîné principalement sur des données issues d’internet, il se peut que l’information générée soit incorrecte, non éthique ou biaisée. Il est donc nécessaire de vérifier le contenu généré.
Bien que les modèles de langage soient entraînés sur d’importantes quantités de données, il pourrait être nécessaire de les entraîner avec de l’information spécifique à un domaine. Dans de tels cas, ils peuvent être réentraînés ou entraînés à partir de zéro. Ce processus est coûteux en ressources et en temps et peut parfois être évité grâce à une meilleure conception des invites.
L’ajustement fin consiste à réentraîner un LLM pré-entraîné sur un ensemble de données spécifique pour répondre à un besoin d’affaires particulier.
Ingénierie d’invite ou ajustement fin, comment choisir ?
D’abord, il est important de déterminer si le LLM a déjà été entraîné sur le type de données pertinentes pour la tâche à accomplir. S’il est suffisamment entraîné, l’ingénierie d’invite devient un outil puissant pour générer du texte et accomplir un large éventail de tâches. Dans ce cas, il est recommandé d’investir des efforts dans la création et le test d’une variété d’invites avant d’envisager l’ajustement fin. Grâce à une sélection stratégique des mots, une structuration de l’invite et l’ajout d’informations contextuelles, le comportement du LLM peut être influencé pour générer des réponses précises, pertinentes et fiables.
Cependant, si la tâche concerne des données externes au corpus d’entraînement ou nécessite des connaissances spécifiques, comme le diagnostic de maladies rares ou l’interprétation de documents juridiques, ou si tous nos efforts d’ingénierie d’invite sont épuisés sans résultat concluant, il est alors conseillé d’investir le temps et les efforts dans l’ajustement fin du modèle avec un jeu de données enrichi. Les détails sur la façon d’ajuster les LLM sortent du cadre de ce blogue.
Utilisation des invites pour pallier les limites du modèle
Les LLM sont des outils statistiques qui traitent des jetons d’entrée pour générer une sortie pertinente. Ils ne possèdent pas d’intelligence générale ni de capacité de raisonnement. Les LLM ont été entraînés sur d’immenses données, mais leur savoir se limite aux faits et concepts rencontrés lors de cet entraînement, ce qui rend leur compréhension incomplète.
- Ils peuvent générer des réponses plausibles et convaincantes, même lorsqu’elles sont erronées, un phénomène appelé hallucination. Demander au modèle de revérifier et valider l’information avant de répondre peut aider à pallier cette limite.
- Bien que les LLM puissent effectuer des opérations mathématiques simples, ils peuvent éprouver des difficultés avec des calculs complexes ou un raisonnement poussé. En appliquant des techniques où le modèle dispose de suffisamment d’informations, d’exemples et d’étapes intermédiaires, sa capacité de raisonnement peut être améliorée. Des invites élaborées et précises permettent d’obtenir de bien meilleurs résultats dans ce domaine.
Conclusion
Les LLM ont révolutionné la compréhension du langage naturel et la génération de texte. L’interaction humaine avec les LLM via du texte structuré se fait par l’entremise d’invites. Ainsi, le rôle d’ingénieur d’invite a émergé pour assurer la liaison entre l’intention humaine et la compréhension machine. Les ingénieurs d’invite conçoivent des invites efficaces pour garantir que le modèle produise des résultats pertinents. Comme les résultats des LLM dépendent fortement des instructions fournies et qu’il n’existe aucune règle ou syntaxe spécifique pour rédiger de bonnes invites, l’ingénierie d’invite est devenue une compétence essentielle pour travailler avec les LLM. L’application adéquate de ces principes et pratiques lors de la création d’invites permet de libérer tout le potentiel des LLM et de générer des sorties pertinentes.
Références
https://www.promptingguide.ai/techniques
Introduction aux grands modèles de langage : ingénierie d’invite et P-Tuning | Blog technique NVIDIA
https://towardsdatascience.com/
Ingénierie d’invite : utiliser les LLM pour générer le contenu souhaité – The New Stack

