

Large Language Models (LLMs) have been trained on a big corpus of data over time using large amounts of compute power. These foundation models exhibit emergent properties that extend beyond language, enabling researchers to leverage their capabilities in breaking down complex tasks, reasoning and solving problems. Interacting with language models differs from machine learning and programming paradigms where computer code is written with formalized syntax to interact with libraries and APIs. In contrast, LLMs interpret the natural language or human-written instructions and perform tasks akin to human behavior. The input provided to an LLM is known as a prompt.
The intent of this blog is to understand how to write, refine and optimize prompts in natural language to achieve the desired goal. We will introduce LLM, explore best practices and principles to create effective prompts and discuss how to optimize a model's performance and mitigate its limitations using prompts.
What is LLM?
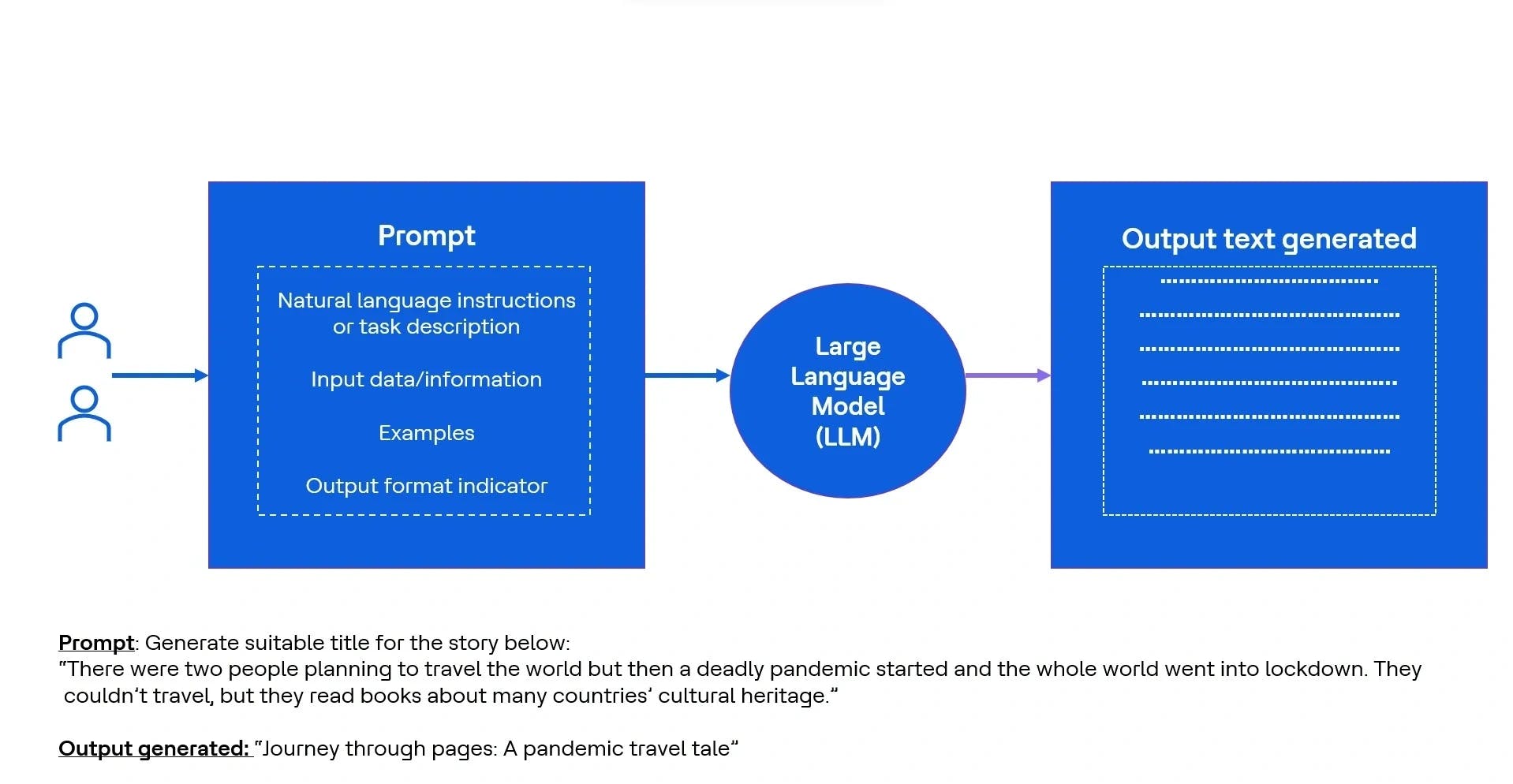
Figure 1 LLM
LLM is a deep learning model that can generate human-like text. It is trained on vast amounts of data from books, articles, websites, documents and beyond. Through exposure to natural language resources, these models develop a profound understanding of human language usage, resembling language experts in grammar, sentence structure and art of conversation.
Since LLMs are trained on an extensive corpus of text, they can generate human-like responses to a wide range of queries or prompts. These models possess an inherent capability to grasp context and generate coherent text based on the input they receive. Leveraging their capabilities combined with their massive size and vast training data, make LLMs an exciting technology with transformative potential.
Prompt engineering and prompts
Prompts are strategically constructed instructions in natural language designed to guide LLM to achieve certain goals.
Prompt engineering, a domain within the area of AI and ML, involves the development and improvement of prompts to enhance the quality of responses and mitigate latency of text generation of LLM. Prompts play a crucial role in setting the direction, tone and scope for the generated response. With the help of prompt engineering, AI experts carefully design prompts to achieve specific goals.
Creating a useful prompt is an iterative process that often requires several revisions of the language to align the behavior of the model with the intended goal.
Use cases of prompt
Natural language is complex and powerful. When it is used to instruct the language models to perform a task, use cases can be unlimited. For example:
| Task | Explanation |
|---|---|
| Summarization |
|
| Inferring |
|
| Transforming |
|
| Expanding |
|
Points to remember when writing good prompts

Figure 2 Best practices for writing good prompt
A well-crafted prompt serves as a context and guiding framework to the model to reach the desired output. Effective structuring and formulating of prompts is crucial for optimizing the performance of LLMs and achieving desired responses. Contrary to popular belief, writing a prompt involves nuanced understanding of language and its various contextual usages. A well-constructed prompt relies on many factors, including:
- Clarity and relevance: Ambiguity in language is a common challenge and accurate prompts help mitigate misinterpretations, leading to more relevant and precise responses.
- Style and tone adaptation: Incorporating relevant references or clear instructions regarding the desired writing style in prompts enables LLMs to generate outputs that align with user expectations. For example specifying the number of words or sentences, format or target audience (asking for information about moon for a 5-year-old vs. for scientists).
- Limited scope: Defining the scope of the prompt to prevent irrelevant or tangential output.
- Diversity: Including a wide range of examples in promptes help LLMs understand the context and generalize concepts.
- Control output quality: Incorporate fact-checking instructions or constraints into prompts facilitates validating information and producing reliable outputs.
- Bias reduction: LLMs being trained mostly on internet data — which contains bias, misinformation and unethical content — is a pressing concern. Prompts can play a pivotal role in guiding LLMs to mitigate the impact of biases and promote fair and objective outputs.
- Optimization and efficiency: LLMs are powerful models that require significant computational resources and time to generate outputs. Crafting well-designed prompts help optimize the performance and improve efficiency of these models. Well-designed prompts provide sufficient context while minimizing unnecessary input, allowing LLMs to generate responses more effectively and promptly. This optimization enhances the overall user experience and increases the practical usability of LLMs.
Now that know about LLMs, prompt engineering and prompts, as well as the importance of correctly crafted prompts, let’s examine important principles and tactics in becoming an effective prompt writer.
Principles of prompt engineering
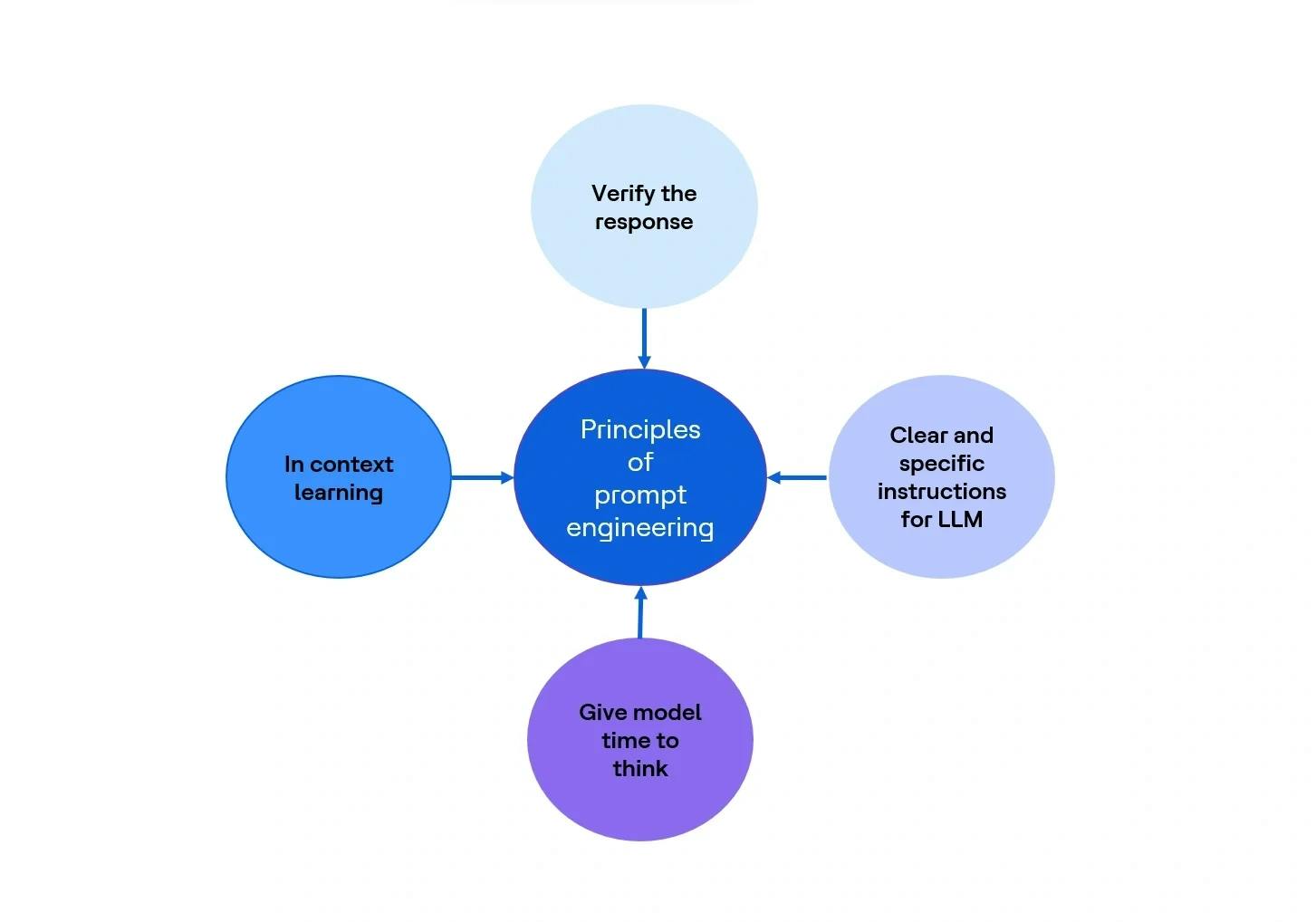
Figure 3 Principles of prompt engineering
Clear and specific instructions for LLM
Clear and specific instructions act as guiding tools to drive the model towards the correct and desired output. It is not necessary to design precise instructions but they should contain all the information imperative to set the context for LLM to generate the desired and relevant output.
- Delimiters or punctuation marks should be used to provide separate parts of inputs. This helps model to understand the difference between the text it needs to work on and the instruction provided by user.
- Ask for structured output like JSON, HTML or List format so you can use it directly wherever required.
- Check for certain conditions before generating response, if required.
Give model time to think
In order to minimize the risk of receiving inaccurate responses from LLMs, users should consider a few points while giving instruction to the model to ensure it has adequate context and reasoning to comprehend the requirement before coming back with a response.
- LLMs need to complete steps to perform a task. There should be no assumptions.
- User can ask a model to make sure that its response is correct before reaching any conclusions.
- Ask the model to act in a specific capacity. For example, “act as data analyst and read the graph” or “act as grade 5 student and read the graph.”
In-context learning
In-context learning is the process of providing examples with reasoning of required output. With in-context learning, users can help LLMs learn more about the task being asked by including examples or additional data in the prompt.
- Zero-shot inference: When no input data is included within the prompt
- One-shot inference: The inclusion of a single example
- Few-shots inference: Sometimes a single example won't be enough for the model to learn what user want it to do,m in which case multiple examples can be given
- If the model isn't performing well when including, say, five or six examples, it is advised to fine-tune the model instead, meaning provide additional training on the model using new data to make it more capable of the specific task
Verify the response
Since the model is trained on the data mostly from internet, it might have incorrect, unethical and biased information. Thus, the generated content needs to be verified.
Though language models are trained on large amounts of data, there may be a need to train it with domain-specific information. In such cases, they can be retrained or trained from scratch. This process is expensive in term of resources and time and can sometimes be avoided by using better prompting.
Fine tuning is re-training of the pre-trained LLM on a specific dataset to meet a specific business need.
Prompt engineering or fine tuning, how to choose?
First, it is important to assess if the LLM has already been trained on the type of data relevant to the task at hand. If it is adequately trained, prompt engineering becomes a powerful tool for generating text and accomplishing a wide range of tasks. In such a scenario, investing efforts in creating and testing a variety of prompts before fine-tuning is advised. Through the strategic selection of words, structuring the prompt and incorporating context-related information in the prompt, the behavior of LLMs can be influenced to generate accurate, relevant and reliable responses.
However, if the task involves data outside the training corpus or requires specific knowledge, such as rare disease diagnosis or legal document interpretation, or if all our efforts to engineer prompts are exhausted and the task is still unaccomplished, it is advised to exhaust time and efforts in fine-tuning the model with an enriched dataset. Details of how to fine-tune LLMs is out of scope for this blog.
Use of prompts to mitigate model limitations
LLMs are the statistical tools that process input tokens to generate relevant output. They do not come with general intelligence and they do not reason. The LLMs are trained on huge data but their knowledge is confined to the facts and concepts encountered in their training data, making their understanding incomplete.
- They can plausibly produce responses with confidence, even when when incorrect, a phenomenon known as hallucination. Instructing a model to recheck and validate the information before generating a response can help to mitigate this limitation.
- While LLMs may perform simple mathematical operations, they may struggle with large number calculations and complex reasoning. By applying techniques where a model is provided enough information, examples and intermediate steps, their reasoning capability can be enhanced. Carefully crafted elaborated prompts can help to achieve a lot in this area.
Conclusion
LLMs have revolutionized the world of natural language understanding and text generation. Human interaction with LLMs using structured text occurs through prompts. Hence, the role of prompt engineer has emerged to bridge the gap between human intent and machine understanding. Prompt engineers craft effective prompts to ensure the model produces relevant outputs. Since outputs from LLMs rely highly on the instructions given to them and there are no specific rules or syntax to write effective prompts, prompt engineering serves as a critical skill for those working with LLMs. Ensuring the correct utilization of these principles and practices when creating prompts facilitates unlocking the full potential of LLMs and generating relevant output.
References
https://www.promptingguide.ai/techniques
An Introduction to Large Language Models: Prompt Engineering and P-Tuning | NVIDIA Technical Blog
https://towardsdatascience.com/
Prompt Engineering: Get LLMs to Generate the Content You Want - The New Stack

