
Les programmeurs tentent d’exploiter l’unité centrale de traitement (CPU) depuis un certain temps déjà en utilisant la programmation parallèle. Néanmoins, elle répond encore bien à la plupart des applications actuelles. À l’ère des charges de travail diversifiées et intensives en calcul, les charges de travail axées sur les données augmentent de façon exponentielle. Pour offrir des performances élevées pour les nouvelles charges de travail spécialisées, le seul CPU ne suffit pas et nous avons besoin d’architectures de calcul diverses. Il nous faut une combinaison d’accélérateurs comme les CPU, unités de traitement graphique (GPU), réseaux logiques programmables (FPGA), etc. L’informatique hétérogène est une excellente solution pour répondre à la demande évolutive.
L’informatique hétérogène désigne les systèmes qui utilisent plus d’un type de processeur ou de cœur. Ces systèmes bénéficient d’une performance accrue ou d’une efficacité énergétique, non seulement en ajoutant le même type de processeurs, mais aussi en incorporant des co-processeurs différents, faisant généralement appel à des capacités de traitement spécialisées pour exécuter certaines tâches. (Wikipedia)
Le GPU est extrêmement utile pour les cas d’utilisation où le traitement de données est hautement parallélisable. Il s’intègre parfaitement aux paradigmes de programmation en intelligence artificielle et en apprentissage automatique. Par exemple, dans l’algorithme ML supervisé « régression linéaire avec variables multiples », le GPU peut effectuer efficacement des calculs de prédiction complexes.
Si vous vous intéressez à la programmation hétérogène en déléguant la charge de travail aux accélérateurs pour obtenir des performances élevées, vous êtes au bon endroit. Nous allons examiner les défis de la pile applicative actuelle, ainsi que les différents modèles de programmation.
De nombreuses grandes organisations proposent des modèles de programmation permettant de déléguer et d’exécuter une partie du code sur des accélérateurs. Quelques-uns des modèles de programmation les plus utilisés sont –
- CUDA (Compute Unified Device Architecture) – CUDA est une plateforme de calcul parallèle et un modèle de programmation créé par NVIDIA pour exploiter les GPU NVIDIA. CUDA aide les développeurs à accélérer leurs applications en utilisant la puissance des accélérateurs GPU. CUDA est une API propriétaire et un ensemble d’extensions du langage qui fonctionne uniquement sur les GPU NVIDIA.
- AMD (Advanced Micro Devices) ROCm – ROCm (Radeon Open Compute Module) est développé par AMD pour utiliser les accélérateurs AMD. Les développeurs peuvent tirer parti de plusieurs domaines, comme le calcul générique sur GPU (GPGPU), le calcul haute performance (HPC) et l’informatique hétérogène. ROCm est officiellement pris en charge uniquement sur les GPU AMD.
- OpenCL (Open Computing Language) – OpenCL est une norme ouverte, sans redevances, fondée sur une API pour la programmation parallèle à usage général sur CPU, GPU et autres processeurs, offrant aux développeurs un accès portable et efficace à la puissance de ces plateformes de traitement hétérogènes. OpenCL est rarement utilisé pour l’apprentissage automatique. Par conséquent, la communauté est réduite et il y a peu de bibliothèques.
- OpenACC – OpenACC est une norme de programmation à base de directives pour le calcul parallèle. Cette norme vise à simplifier la programmation parallèle de systèmes hétérogènes. La simplicité et la portabilité qu’offre le modèle de programmation OpenACC se font parfois au détriment de la performance.
Chacune des solutions mentionnées ci-dessus repose sur des outils et des langages spécifiques. Imaginez les défis que doivent relever les développeurs pour les regrouper. Les difficultés se multiplient avec les langages propriétaires moins connus. Il est toujours difficile de savoir si la prochaine version prendra en charge les anciennes fonctionnalités ou non.
oneAPI, accompagné de data parallel C++, aborde ce problème et apporte productivité et performance optimale à travers l’architecture. Il s’agit d’un standard ouvert, donc accessible à la communauté pour favoriser l’innovation collective.
oneAPI – oneAPI est un modèle de programmation ouvert et inter-architecture qui permet aux développeurs d’utiliser une seule base de code pour de multiples architectures. Le résultat est un calcul accéléré sans dépendance à un fournisseur. Il inclut le langage data parallel C++, basé sur le C++ standard et SYCL (prononcé « sickle »).
Explorons en détail le langage central de oneAPI, data parallel C++.
DPC++ (Data Parallel C++) est le langage central de oneAPI. Pourquoi est-il important pour l’industrie, et pourquoi est-ce un facteur de changement? Commençons par comprendre le problème auquel s’attaque oneAPI et comment il s’y prend.
Les charges de travail axées sur les données ont connu une évolution spectaculaire au cours des dernières années. Elles augmentent de façon exponentielle et sont de plus en plus diversifiées. Pour offrir des performances élevées pour les nouvelles charges de travail spécialisées, une architecture de calcul diversifiée est requise. D’où un changement observé également dans l’industrie du matériel. Nous avons des CPU pour la programmation scalaire et vectorielle. Ensuite, viennent les GPU et accélérateurs IA, bons pour le vectoriel et la matrice. Le FPGA introduit une toute nouvelle approche. Les accélérateurs peuvent être intégrés, comme les vecteurs dans le CPU, ou de type externe, comme GPU, FPGA, etc. Chaque architecture est optimale pour un type de charge de travail, aucune ne couvre tous les besoins!
La pile applicative que nous avons utilisée repose sur des éléments fondamentaux que sont les langages et bibliothèques, ou des frameworks intermédiaires, pour créer une abstraction, et des applications compilées qui ciblent des architectures spécifiques.
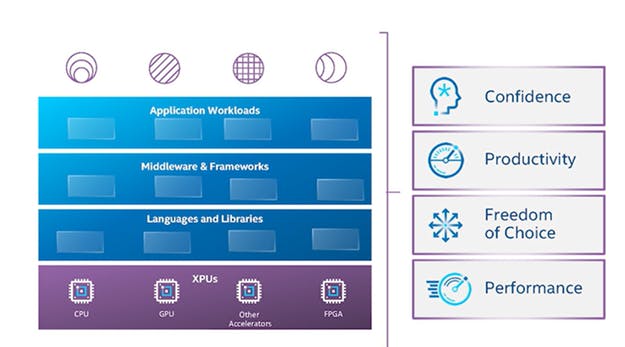
Figure 1 : Pile applicative traditionnelle (source : Modèle de programmation oneAPI)
Ce n’est pas comme si nous n’avions pas encore obtenu de bonnes performances. Avec le CPU, openMP est utilisé pour extraire la performance. CUDA est présent sur le marché depuis un moment pour le GPU NVIDIA.
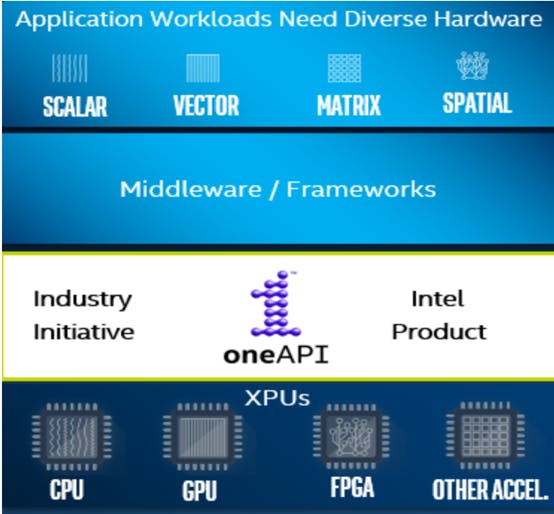
Figure 2 : Pile applicative avec oneAPI. (Source : Modèle de programmation oneAPI)
DPC++ est l’implémentation de SYCL par oneAPI. Il s’appuie sur les avantages de productivité du C++ moderne et sur des constructions familières et intègre la norme SYCL pour le parallélisme de données et la programmation hétérogène. SYCL permet à l’application d’utiliser différents dispositifs hétérogènes simultanément. Des implémentations SYCL sont disponibles auprès d’un nombre croissant de fournisseurs. Quelques-uns sont listés ci-dessous :
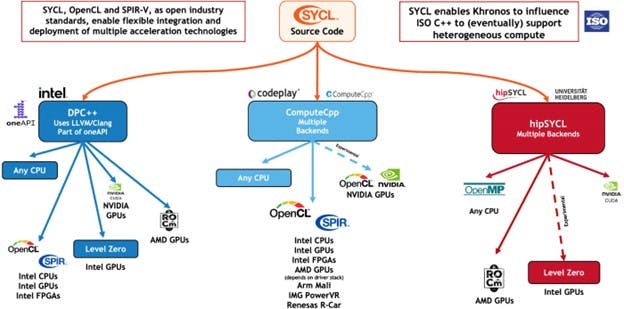
Figure 3 : Écosystème des compilateurs SYCL (Source : Khronos.org/sycl).
Data parallel C++ a C++ et SYCL comme base, ce qui le rend interopérable avec de nombreux autres modèles de programmation et langages très courants comme Fortran, MPI et, bien sûr, C++. DPC++ est une source unique, ce qui signifie que le code hôte et le code appareil peuvent être placés dans le même fichier et compilés avec une seule invocation du compilateur. Un hôte est un ordinateur, généralement un système basé sur CPU exécutant la partie principale d’un programme. Un appareil est un accélérateur qui peut exécuter rapidement un sous-ensemble d’opérations, généralement plus efficacement que les CPU du système. Chaque appareil contient une ou plusieurs unités de calcul capables d’exécuter plusieurs opérations en parallèle.
Le programme est invoqué sur l’ordinateur hôte et délègue le calcul à l’accélérateur. Un programmeur utilise les abstractions de file, tampon, appareil et noyau de SYCL pour diriger quelles parties du calcul et des données doivent être déléguées et comment elles partageraient les données. DPC++ est le langage de choix pour la programmation de type GPU, comme l’écriture de noyaux et la délégation au dispositif. En fin de compte, DPC++ est le langage de choix sous le nom oneAPI, si quelqu’un veut utiliser un FPGA, un accélérateur d’IA ainsi qu’un CPU et un GPU.
DPC++ est un langage de haut niveau conçu pour cibler des architectures hétérogènes et tirer parti du parallélisme de données. Comprenons la structure d’un programme DPC++.
Inclure le fichier d’en-tête et l’espace de noms pour fournir des modèles et des définitions de classe. Utiliser un tampon/accessor ou la mémoire partagée unifiée (USM) pour accéder à la mémoire entre l’hôte et le dispositif. Créer une file de commandes pour des dispositifs spécifiques à l’aide d’un sélecteur de dispositif pour soumettre le noyau à l’exécution. Envoyer le noyau à l’exécution avec single task, noyau en parallèle de base, noyau en ND-range ou noyau hiérarchique. Copier le résultat de l’appareil vers l’hôte en utilisant USM ou un accessor.
DPC++ est relativement nouveau dans l’industrie, et il reste encore beaucoup de chemin à parcourir. Beaucoup de gens ne sont pas encore au courant ou pas assez formés pour commencer à l’utiliser efficacement. Mais il a le potentiel d’apporter une différence.
En conclusion, oneAPI a accompli un travail formidable pour créer une expérience de développement commune à travers les architectures d’accélérateurs. Maintenant, plus de temps peut être consacré à l’innovation et à l’optimisation et moins à la réécriture du code. Avec une base de code unique, le code appareil et le code hôte peuvent exister dans le même fichier. DPC++ est conçu pour exploiter pleinement la valeur du matériel, offrant la réutilisation de code performant entre les dispositifs cibles.
Références
- Spécifications | oneAPI
- oneAPI : Une nouvelle ère de l’informatique hétérogène (intel.com)
- Compilation multi-architecture : Intel® oneAPI DPC++/C++ Compiler
- Anatomie d’un programme DPC++ — Documentation de référence DPC++ (oneapi-src.github.io)
- Parallélisme de données en C++ avec SYCL* (intel.com)
- Livre - Implémentation parallèle sur GPU des algorithmes d’intelligence en essaim par Ying Tang
- La spécification OpenCL™ (khronos.org)
- https://www.nvidia.com/
- Guide de programmation et des meilleures pratiques OpenACC
- Aperçu de SYCL - The Khronos Group Inc
- Informatique hétérogène - Wikipédia

