
Programmers have been trying to exploit the Central Processing Unit(CPU) for quite some time by using parallel programming. Nonetheless, it still performs well for most of the applications running today. In the age of diverse and computation-intensive workloads, data-driven workloads are increasing exponentially. To deliver high performance for emerging specialized workloads, only CPU is not enough, and we require diverse compute architectures. We need a blend of accelerators like CPUs, Graphics Processing Unit(GPUs), Field Programmable Gate Arrays(FPGAs) etc. Heterogeneous computing is a great way to cater to the evolving demands.
Heterogeneous computing refers to systems that use more than one kind of processor or core. These systems gain performance or energy efficiency not just by adding the same type of processors, but by adding dissimilar co-processors, usually incorporating specialized processing capabilities to handle particular tasks. (Wikipedia)
GPU is extremely useful for highly parallelizable data processing use cases. It fits perfectly with AI and ML programming paradigms. For example, in the supervised ML algorithm “linear regression with multiple features”, GPU can efficiently perform complex prediction calculations.
If you are interested in heterogeneous programming by offloading the workload to accelerators to achieve high performance, you are at the right place. We will be looking into the challenges of the current application stack, along with the various programming models.
Many leading organizations provide programming models to offload and execute part of code on accelerators. Some of the widely used programming models are -
- CUDA(Compute Unified Device Architecture) – CUDA is a parallel computing platform and programming model created by NVIDIA to utilize NVIDIA GPUs. CUDA helps developers speed up their applications by harnessing the power of GPU accelerators. CUDA is a proprietary API and set of language extensions that works only on NVIDIA's GPUs.
- AMD(Advanced Micro Devices) ROCm – ROCm(Radeon Open Compute Module) is developed by AMD to utilize AMD accelerators. Developers can take advantage of several domains, such as general-purpose GPU(GPGPU), high-performance computing (HPC), and heterogeneous computing. ROCm officially supports only AMD GPUs.
- OpenCL(Open Computing Language) – OpenCL is an open, royalty-free API-based standard for general-purpose parallel programming across CPUs, GPUs, and other processors, giving software developers portable and efficient access to the power of these heterogeneous processing platforms. OpenCL is rarely used for machine learning. As a result, the community is small, with few libraries.
- OpenACC – OpenACC is a directive-based programming standard for parallel computing. The standard is designed to simplify the parallel programming of heterogeneous systems. The simplicity and portability that OpenACC’s programming model provides sometimes comes at the cost of performance.
Every single solution mentioned above has its own specific silos of tools and languages. Imagine the challenges faced by developers to bring these together. The challenges grow multifold with the less-understood proprietary languages. It is always difficult to gauge whether the next version will support the old features or not.
oneAPI, along with data parallel C++, is addressing this issue and bringing in productivity and optimal performance across the architecture. It is an open standard and hence available to the community to come together and innovate.
oneAPI- oneAPI is an open, cross-architecture programming model that gives developers the flexibility to use a single code base across multiple architectures. The result is an accelerated compute without vendor lock-in. It includes data parallel C++ language, which is based on standard C++ and SYCL(pronounced as ‘sickle’).
Let’s explore the core language of oneAPI, data parallel C++, in detail.
DPC++ (Data Parallel C++) is the core language of oneAPI. Why is it important to the industry, and what makes it a game changer? First, let’s try to understand the problem oneAPI is trying to solve and how.
Data-centric workloads have evolved dramatically over the past couple of years. These workloads are increasing exponentially and are diverse in nature. To deliver high compute performance for emerging specialized workloads, diverse compute architecture is required. Hence, we have witnessed a change in the hardware industry as well. We have CPUs for scalar and vector programming. Then comes GPU and AI accelerators that are good for vector and matrix. FPGA brings in a completely different paradigm. Accelerators can be integrated like vectors in CPU or attached types like GPU, FPGA etc. Each architecture serves best with one type of workload, and none serves all!
The application stack that we have been working with is built on top of foundational elements of languages and libraries, or middleware frameworks, to create an abstraction, and compiled applications which are targeting specific architecture.
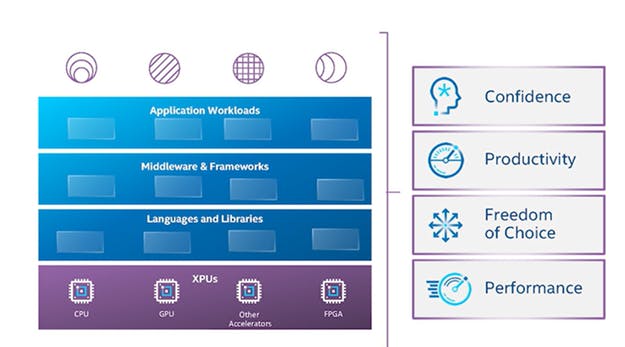
Figure 1: Traditional Application Stack (source: oneAPI Programming Model)
It’s not like we haven’t been able to gain performance yet. With CPU, openMP is being used to extract performance. CUDA has been in the market for quite some time for NVIDIA GPU.
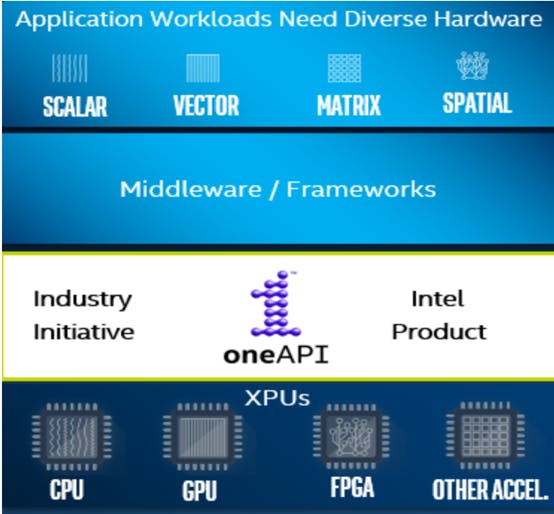
Figure 2: Application stack with oneAPI. (Source: oneAPI Programming Model)
DPC++ is oneAPI's implementation of SYCL. It is based on the modern C++ productivity benefits and familiar constructs, and it incorporates the SYCL standard for data parallelism and heterogeneous programming. SYCL enables the application to use different heterogeneous devices simultaneously. SYCL implementations are available from an increasing number of vendors. Some of them are listed below:
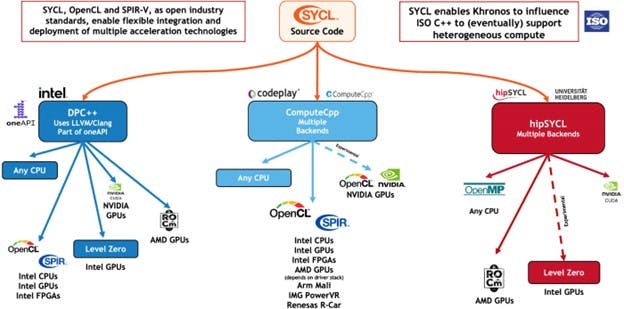
Figure 3: The SYCL compiler ecosystem (Source: Khronos.org/sycl).
Data parallel C++ has C++ and SYCL as the base, which makes it interoperable with a lot of other very common programming models and languages like Fortran, MPI and, of course, C++. DPC++ is a single source, which means the host code and the device code can be placed in the same file and compiled with a single invocation of the compiler. A host is a computer, typically a CPU-based system executing the primary portion of a program. A device is an accelerator that can quickly execute a subset of operations typically more efficiently than the CPUs in the system. Each device contains one or more compute units that can execute several operations in parallel.
The program is invoked on the host computer and offloads computation to the accelerator. A programmer uses SYCL’s queue, buffer, device, and kernel abstractions to direct which parts of the computation and data should be offloaded and how they would share data. DPC++ is the language of choice for GPU style of programming, like writing kernels and offloading to the device. In the end, anyway, DPC++ is the language of choice under the oneAPI name, if someone wants to utilize FPGA, AI accelerator along with CPU and GPU.
DPC++ is a high-level language designed to target heterogeneous architectures and take advantage of data parallelism. Let’s understand the DPC++ program structure.
Include header file and namespace to provide templates and class definitions. Use buffer/accessor or USM (unified shared memory) to access memory between host and device. Create a command queue for specific devices through device selector to submit the kernel for execution. Send the kernel for execution by using single task, basic parallel kernel, ND-range kernel, or hierarchical kernel. Copy the result from the device to the host using USM or an accessor.
DPC++ is relatively new to the industry, and there is still a long way to go. Many people are still not aware or are not trained enough to start using it effectively. But it comes with the potential to create a difference.
To conclude, oneAPI has done a tremendous work to create a common development experience across accelerator architectures. Now more time can be spent on innovation and optimization and less on rewriting the code. With a single code base, both device code and host code can exist in the same file. DPC++ is designed to realize the full value of hardware, delivering performance code reusability across target devices.
References
- Specifications | oneAPI
- oneAPI: A New Era of Heterogeneous Computing (intel.com)
- Compile Cross-Architecture: Intel® oneAPI DPC++/C++ Compiler
- Anatomy of a DPC++ Program — DPC++ Reference documentation (oneapi-src.github.io)
- Data Parallelism in C++ using SYCL* (intel.com)
- Book - GPU-based Parallel Implementation of Swarm Intelligence Algorithms by Ying Tang
- The OpenCL™ Specification (khronos.org)
- https://www.nvidia.com/
- OpenACC Programming and Best Practices Guide
- SYCL Overview - The Khronos Group Inc
- Heterogeneous computing - Wikipedia

