

Introduction
Les grands modèles de langage (LLMs) révolutionnent les industries, des chatbots à la recherche scientifique. Leur capacité à traiter d’énormes ensembles de données et à générer du texte semblable à celui des humains en a fait des outils indispensables. Cependant, leur efficacité dépend de leur fiabilité et de leur respect de l’éthique. Pour exploiter pleinement la puissance des LLMs, des tests rigoureux sont essentiels.
Qu’est-ce que le test des LLM ?
Le test des LLM consiste à évaluer les grands modèles de langage afin de s’assurer qu’ils performent comme prévu, qu’ils fournissent des réponses exactes et pertinentes et qu’ils respectent les principes éthiques. Il s’agit d’un processus complexe qui comprend :

Pourquoi le test des LLM est-il crucial ?
Le test des LLM assure la fiabilité, l’exactitude, l’équité du modèle et la conformité avec les principes d’IA responsable. Sans une évaluation approfondie, les risques incluent des résultats inexacts (par ex., réponses biaisées, désinformation) et des échecs dans des applications critiques. Les tests permettent de détecter les problèmes précocement, permettant aux développeurs d’affiner les modèles et d’instaurer la confiance envers l’IA.
Comment évaluons-nous les LLM ?
L’évaluation des LLM mesure la performance, l’IA responsable et la fonctionnalité afin de garantir que les modèles répondent aux exigences des utilisateurs, à l’éthique et aux exigences opérationnelles. Une définition claire de l’objectif du modèle (par ex., contenu créatif, réponses factuelles) est cruciale pour choisir les bonnes méthodes et métriques d’évaluation.
Mécanisme d’évaluation
- Évaluation hors ligne : Teste le modèle durant le développement à l’aide d’ensembles de données prédéfinis pour cibler des axes d’amélioration
- Évaluation en ligne : Évalue la performance en conditions réelles en analysant les journaux d’interactions des utilisateurs
Intégration CI/CD : Intègre des tests automatisés dans le pipeline CI/CD pour une amélioration continue et un déploiement rationalisé
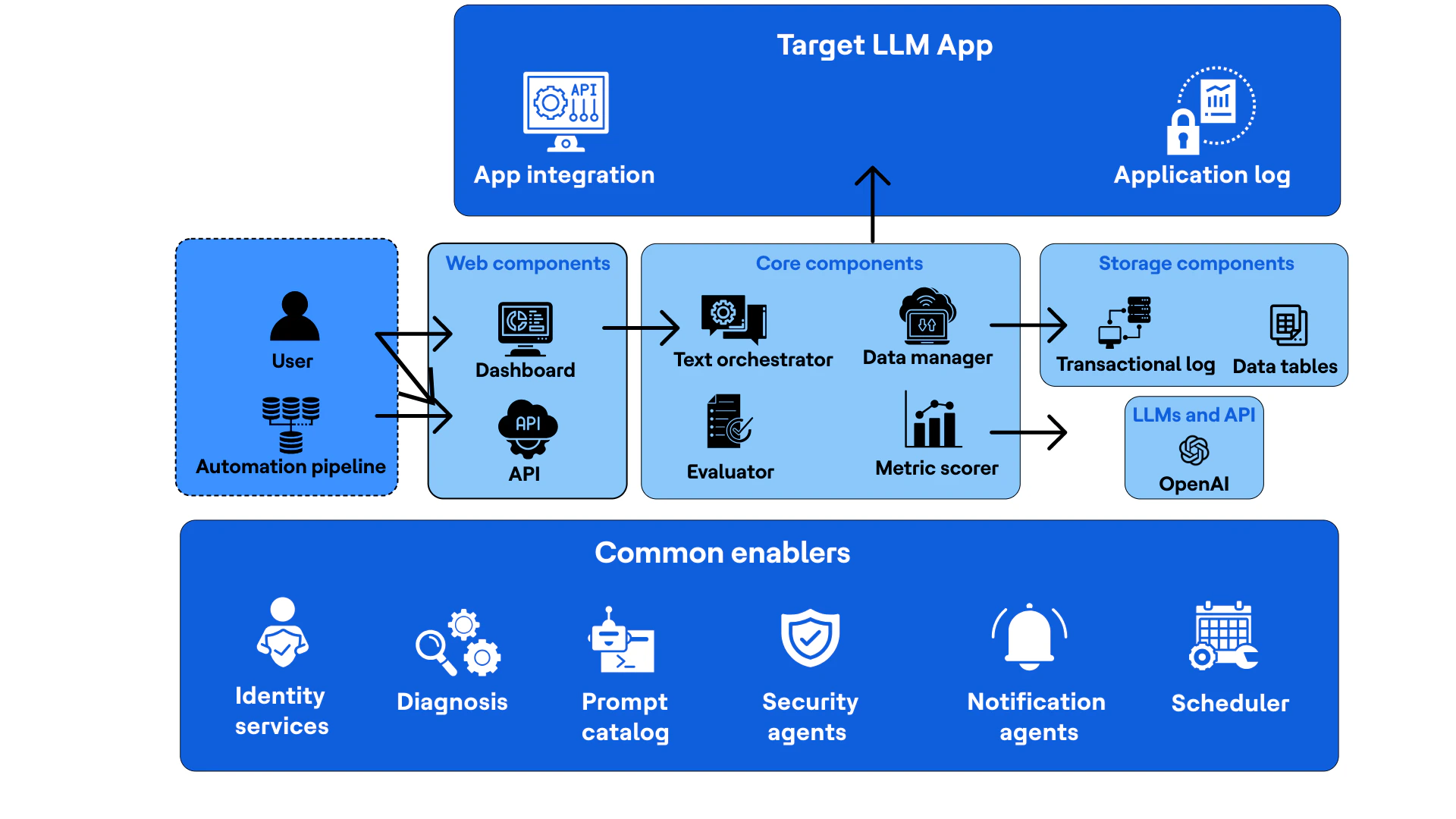
Que mesurons-nous ?
L’évaluation des LLM se concentre sur :
- Correction fonctionnelle : S’assurer que le modèle agit comme prévu
- IA responsable : Respecter les considérations éthiques, l’équité et la sécurité
- Efficacité de performance : Évaluer l’efficacité, la scalabilité et l’utilisation des ressources du modèle
Catégorie | Composantes | |
| Tests fonctionnels | Validation des fonctionnalités | |
| Validation des invites | ||
| Tests exploratoires | ||
| Tests de régression | ||
| Tests unitaires | Tests adversariaux, tests basés sur les propriétés, tests basés sur des exemples, auto-évaluation | |
| Tests d’utilisabilité | Tests d’interface utilisateur, gestion des erreurs, prise en compte du contexte, accessibilité | |
| Exactitude des réponses | Pertinence, cohérence, exhaustivité, constance | |
| Analyse comparative | ||
| Validation de l’intégration | ||
| Validation multimodale | ||
| Tests d’IA responsable | Biais, équité, toxicité, transparence, responsabilité, inclusion, respect de la vie privée, sécurité, fiabilité et sécurité | |
| Tests de performance | Latence | Débit, temps de réponse |
| Scalabilité | Charge utilisateur, charge réseau, grands volumes de données | |
| Utilisation des ressources | CPU, GPU, mémoire, utilisation du disque | |
Indices pour les piliers de l’IA :
Piliers de l’IA | Description |
|---|---|
IA explicable | Mesure la clarté des décisions du modèle |
IA équitable | Quantifie le niveau d’équité dans les prédictions du modèle |
IA sécurisée | Évalue la robustesse du modèle face aux menaces |
IA éthique | Mesure la conformité avec les lignes directrices éthiques |
Évaluation globale :
Combine les indices individuels (explicabilité, équité, sécurité, éthique) pour une évaluation globale.
Seuils :
- Indice ≥ x : Indique la fiabilité et la préparation pour la certification
- Indice < x : Suggère la nécessité d’apporter des améliorations
Méthodologies de test
- Tests automatisés : Utilisent des ensembles de données prédéfinis et des mesures de référence (par ex. : BLEU, ROUGE, Perplexity) pour évaluer la performance des LLM
- Évaluation par les pairs LLM : Utilisent d’autres LLM pour évaluer des LLM, au moyen de critiques, de rubriques ou de métriques
- Tests fondés sur des scénarios : Simulent des cas réels pour évaluer l’utilité concrète
Conclusion
Des tests rigoureux des grands modèles de langage (LLMs) sont impératifs afin d’assurer leur fiabilité, leur équité et leur alignement avec les principes éthiques. En évaluant systématiquement les LLM selon les axes fonctionnels, d’IA responsable et de performance, les organisations peuvent détecter et traiter les biais potentiels, inexactitudes et vulnérabilités de sécurité.
Un cadre de test robuste, englobant des évaluations hors ligne et en ligne ainsi que l’intégration au pipeline CI/CD, est essentiel pour l’amélioration continue et le déploiement. En donnant la priorité aux tests des LLM, les organisations peuvent libérer tout le potentiel de l’IA, offrir des solutions novatrices et instaurer la confiance chez les utilisateurs. À mesure que le domaine de l’IA évolue, notre engagement envers des tests rigoureux doit également évoluer, afin de garantir le développement d’applications LLM éthiques, fiables et bénéfiques.
