

La plupart des initiatives d'apprentissage automatique rencontrent des défis non pas lors du développement du modèle, mais plutôt lors du déploiement en production et de la maintenance opérationnelle à long terme.
Alors que les expériences réalisées dans des notebooks peuvent donner des résultats prometteurs et que les démonstrations de preuve de concept peuvent fonctionner comme prévu, les environnements de production exigent des considérations opérationnelles rigoureuses :
- Cohérence des données : Assurer des flux de données reproductibles lors des exécutions de pipeline
- Gestion des versions des caractéristiques : Maintenir l’alignement entre l’ingénierie des variables à l’entraînement et à l’inférence
- Gouvernance : Établir une gestion traçable des versions du modèle et des flux d’approbation
- Interprétabilité : Fournir des explications prédictives compréhensibles pour les parties prenantes
- Assurance qualité : Mettre en œuvre des mécanismes proactifs de détection de la dérive
- Automatisation : Réduire au minimum les interventions manuelles à chaque étape du cycle de vie du modèle
Ces exigences opérationnelles soulignent l’importance essentielle du MLOps.
Cette mise en œuvre exploite un scénario de désabonnement client dans les télécommunications comme base pratique pour démontrer le flux de travail. Toutefois, le cas d’utilisation précis sert surtout de support pour illustrer l’objectif plus large : établir un cycle de vie MLOps robuste avec des contrôles systématiques pour l’entraînement, le déploiement, la surveillance et l’amélioration continue des modèles.
De plus, l’intégration stratégique de capacités d’IA agentique à des étapes clés du pipeline améliore l’efficacité opérationnelle en réduisant les charges de révision manuelle et en rendant les résultats plus accessibles tant pour les praticiens techniques que pour les parties prenantes d’affaires.
Pourquoi la production ML exige plus que l’entraînement du modèle
Dans les contextes de déploiement en entreprise, les défis proviennent rarement de la seule performance du modèle. Plutôt, ils émergent d’un écosystème opérationnel inadéquat autour du modèle.
Parmi les lacunes fréquemment observées :
- Incohérence des données : Variations dans le traitement et le prétraitement des données à travers les exécutions de pipeline
- Déficit de traçabilité : Suivi de lignée insuffisant entre les ensembles de données, les expériences et les versions des modèles
- Goulots d’étranglement manuels : Procédures d’approbation et de mise en production dépendantes de l’humain
- Limites d’explicabilité : Un manque de transparence affaiblit la confiance des parties prenantes dans les prédictions
- Surveillance réactive : La détection de dérive se produit après la dégradation des performances données aux résultats d’affaires
- Charge opérationnelle : Efforts manuels excessifs requis pour l’examen, la surveillance et la production de rapports
Par conséquent, le besoin fondamental va au-delà de l’entraînement du modèle; il vise à établir un cycle de vie reproductible et vérifiable permettant aux équipes d’itérer, valider, approuver, déployer, surveiller et améliorer systématiquement les systèmes ML.
Notre approche MLOps
L’infrastructure ML en production ne devrait pas être conceptualisée simplement comme un modèle associé à un point d’inférence. Elle doit plutôt être architecturée comme un cycle de vie gouverné comportant des points de contrôle explicites allant de l’ingestion de données à la surveillance post-déploiement.
Cette mise en œuvre structure le cycle de vie autour de six piliers fondamentaux :
- Flux de données gouverné : Assurer la qualité, la cohérence et la traçabilité des données
- Cycle de vie du modèle suivi : Maintenir des versions et des pistes d’audit complètes
- Voie de mise en production contrôlée : Mettre en place un déploiement à paliers avec processus d’approbation
- Prédictions explicables : Offrir des résultats interprétables pour assurer la confiance des parties prenantes
- Surveillance continue : Permettre la détection proactive de la dégradation des performances
- AgentOps : Tirer parti de l’automatisation intelligente agentique pour alléger la charge opérationnelle
Ce cadre représente un changement de paradigme, passant du développement ponctuel de modèles à des opérations ML systématiques et de niveau production.
Le désabonnement dans le secteur des télécommunications comme cas d’utilisation
Pour ancrer le cycle de vie dans un contexte d’affaires concret, cette mise en œuvre utilise un scénario de prédiction du désabonnement client en télécommunications.
La base est l’ensemble de données de désabonnement telco d’IBM, qui comprend les données démographiques clients, les configurations de service, l’information de facturation et les indicateurs de désabonnement. Dans ce flux, le cas d’utilisation du désabonnement sert principalement d’ancrage d’affaires, apportant un contexte pratique alors que la principale proposition de valeur réside dans la démonstration de la façon dont les modèles sont systématiquement construits, entraînés, déployés, surveillés et développés grâce au cadre MLOps. Le livrable consiste en un score de risque de désabonnement, accompagné d’informations contextuelles pour soutenir l’examen et les stratégies de rétention.
Cycle de vie MLOps en pratique
L’architecture du flux de travail met en œuvre un cycle de vie complet couvrant la mise à disposition de l’infrastructure et la préparation des données, jusqu’au développement du pipeline, à l’entraînement, au déploiement, à la surveillance, et à l’évolution itérative du modèle dans un système en boucle fermée. Cette structure est volontairement transparente tant dans sa conception conceptuelle que dans sa réalisation technique.
La valeur de cette architecture ne réside pas dans la quantité de services employés, mais dans la clarté de la mission assignée à chaque étape du cycle de vie :
- Gestion des données et des caractéristiques
Le flux débute avec l’ingestion des données, le prétraitement et l’ingénierie de variables. Un magasin de caractéristiques centralisé assure la cohérence entre les environnements d’entraînement et d’inférence, réduisant substantiellement le risque de divergence de variables. - Développement du modèle piloté par les pipelines
Le développement suit des étapes de pipeline structurées, notamment le prétraitement, l’entraînement, l’évaluation et l’enregistrement. Cette approche garantit la reproductibilité et favorise des processus d’examen systématique. - Enregistrement et approbation gouvernés
Après évaluation, les modèles accèdent à l’enregistrement officiel et aux paliers d’approbation avant la mise en production. Ce cadre de gouvernance renforce le contrôle des versions, la traçabilité et la rigueur de la mise en production. - Déploiement validé
Les modèles sont déployés dans des environnements d’inférence avec validation intégrée et surveillance de la santé en temps réel. Les fonctionnalités d’explicabilité sont intégrées dans le parcours de prédiction, garantissant aux utilisateurs des informations contextuelles et non de simples scores opaques. - Surveillance continue et gestion de la dérive
La surveillance post-déploiement évalue en continu la qualité des données entrantes, détecte la dérive des distributions et identifie les écarts sur la base des seuils définis. L’automatisation des alertes et la relance de l’entraînement permettent une intervention proactive, complétant la boucle de rétroaction en production. - Évolution itérative des modèles
Le cycle de vie dépasse le premier déploiement pour soutenir l’amélioration continue. Un deuxième cycle facilite le raffinement du modèle, l’évaluation champion/ challenger et la stratégie de déploiement progressif qui minimise les risques.
Ce changement de paradigme réinvente la production ML non pas comme un événement ponctuel, mais comme une discipline opérationnelle continue.

Figure 1. Cycle de vie MLOps de bout en bout avec support IA agentique à travers les données, l’entraînement, le déploiement, la surveillance et l’évolution du modèle
Services AWS appuyant le flux de travail
Bien que les services AWS fournissent l’infrastructure essentielle pour le cycle de vie ML, ils agissent en tant que facilitateurs plutôt que comme point central de cette architecture.
Services principaux :
- Amazon S3 – Stockage pour les ensembles de données, les artefacts de modèles et les résultats
- SageMaker Feature Store – Garantit la cohérence des variables entre l’entraînement et l’inférence
- SageMaker Pipelines – Orchestration des flux de travail de bout en bout
- SageMaker Experiments – Suit et compare les exécutions expérimentales
- SageMaker Model Registry – Gère la gestion des versions et les processus d’approbation des modèles
- SageMaker Endpoints – Sert des modèles pour l’inférence
- SageMaker Clarify – Offre l’explicabilité des prédictions
- SageMaker Model Monitor – Détecte la dérive et surveille la qualité du modèle
- CloudWatch, Lambda et SNS – Permettent l’alerte et l’automatisation évènementielle
- Amazon Bedrock – Alimente la couche agentique pour la révision, le triage et l’interprétation d’affaires
La proposition de valeur de l’IA agentique
C’est ici que notre approche diverge des mises en œuvre MLOps traditionnelles.
Le MLOps traditionnel améliore de façon marquée la gouvernance, la gestion des mises en production et l’observabilité. Toutefois, une part importante d’efforts manuels persiste tout au long du cycle de vie ML. Les équipes consacrent encore du temps à la validation de la qualité des données, à la comparaison des expériences, à la révision des résultats d’entraînement, à la validation des déploiements, à l’interprétation des alertes de dérive et à la traduction des prédictions techniques en recommandations d’affaires actionnables. La couche agentique cible ces inefficacités résiduelles.
Notre mise en œuvre déploie de manière stratégique des agents IA aux endroits où la charge de révision manuelle est la plus forte :
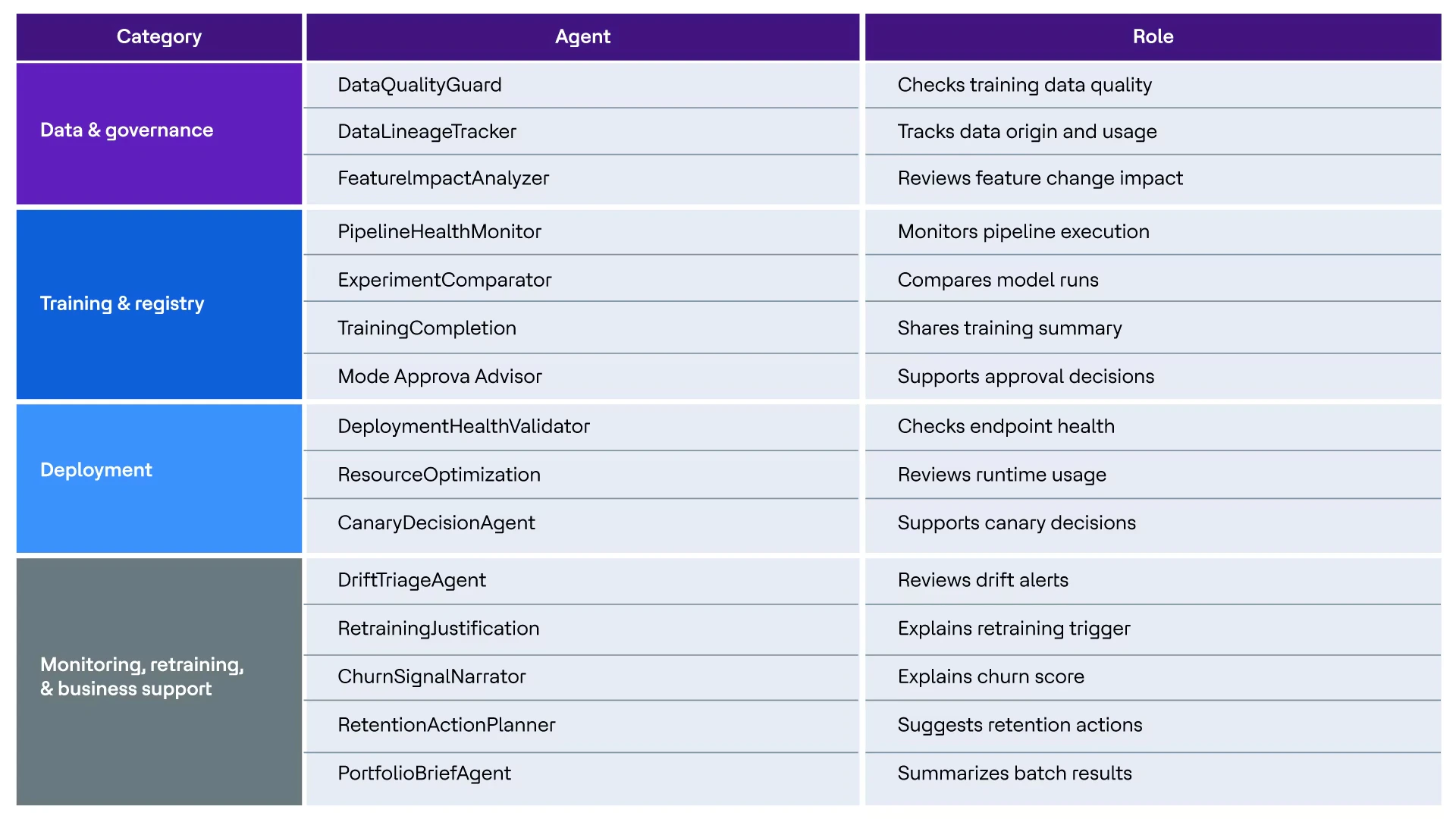
Figure 2. Soutien IA agentique
L’infrastructure MLOps demeure intacte et essentielle. Les agents accélèrent les cycles de révision qu’elle comporte.
Pourquoi cela compte pour chaque persona
Un atout majeur de ce cadre est sa conception multi-partie prenante. Ce n’est pas une solution en science des données en silo. Elle répond aux besoins spécifiques de chaque rôle impliqué dans le cycle de vie ML.
- Les scientifiques des données exigent des flux reproductibles pour l’entraînement, le suivi des expériences et la comparaison des modèles
- Les ingénieurs ML ont besoin de parcours rationalisés d’exécution de pipeline jusqu’au déploiement et à la surveillance
- Les ingénieurs plateformes et DevOps requièrent des contrôles robustes sur la santé en temps réel, la gestion des accès, la journalisation et l’observabilité
- Les parties prenantes d’affaires veulent des résultats de modèles interprétables, actionnables et directement utilisables dans la prise de décision
Cette cohérence interfonctionnelle est fondamentale à la valeur du cadre. Un système ML en production qui ne sert que l’équipe ML n’est pas vraiment prêt pour la production.
Pourquoi le deuxième cycle compte
L’ajout d’un deuxième cycle d’itération démontre une réelle maturité architecturale.
Le premier cycle établit le modèle de référence en production. Le second cycle incorpore des signaux opérationnels additionnels, procède à une comparaison rigoureuse avec le modèle initial et opère un déploiement progressif contrôlé.
Cette distinction est essentielle car elle illustre une véritable maturité ML, soit savoir aller au-delà du premier déploiement, démontrer une amélioration encadrée et systématique dans le temps, avec validation appropriée à chaque étape.
Conclusion
On ne définit pas la ML en production par le seul fait qu’un modèle a été déployé. Elle se définit par le fait que ce modèle opère dans un cycle reproductible, inspectable et gouverné—que les équipes peuvent exécuter, approuver, déployer, surveiller et améliorer continuellement en toute confiance, sans dépendre de processus manuels ad hoc. C’est ce problème fondamental que vise à résoudre le MLOps.
La couche IA agentique complète ce cycle de vie fondamental. Son objectif n’est pas de remplacer la discipline MLOps, mais d’alléger la charge liée aux révisions répétitives qui persistent même dans les flux de travail bien structurés, et de rendre les résultats techniques plus accessibles et actionnables tant pour les équipes techniques que d’affaires.




