

Most machine learning initiatives encounter challenges not during model development, but during production deployment and long-term operational maintenance.
While notebook experiments may yield promising results and proof-of-concept demonstrations may function as intended, production environments demand rigorous operational considerations:
- Data consistency: Ensuring reproducible data flows across pipeline executions
- Feature versioning: Maintaining alignment between training and inference feature engineering
- Governance: Establishing traceable model versioning and approval workflow
- Interpretability: Delivering business-stakeholder-friendly prediction explanation
- Quality assurance: Implementing proactive drift detection mechanisms
- Automation: Minimizing manual intervention throughout the model lifecycle
These operational requirements underscore the critical importance of MLOps.
This implementation leverages a telecom customer churn scenario as a practical foundation for demonstrating the workflow. However, the specific use case serves primarily as a vehicle for illustrating the broader objective: establishing a robust MLOps lifecycle with systematic controls for model training, deployment, monitoring and iterative improvement.
Additionally, the strategic integration of Agentic AI capabilities at key pipeline stages enhances operational efficiency by reducing manual review overhead and improving the accessibility of outputs for both technical practitioners and business stakeholders.
Why Production ML Requires More Than Model Training
In enterprise deployment contexts, challenges rarely stem solely from model performance. Rather, they emerge from an inadequate operational model ecosystem.
Frequently observed gaps include:
- Data inconsistency: Variations in data processing and preprocessing logic across pipeline executions
- Traceability deficits: Insufficient lineage tracking across datasets, experiments and model versions
- Manual bottlenecks: Human-dependent approval and release procedures
- Explainability limitations: Insufficient transparency undermines stakeholder confidence in predictions
- Reactive monitoring: Drift identification occurring after performance degradation has impacted business outcomes
- Operational overhead: Excessive manual effort required for review, monitoring and reporting activities
Consequently, the fundamental requirement extends beyond model training to encompass the establishment of a repeatable, auditable lifecycle that enables teams to systematically iterate, validate, approve, deploy, monitor and enhance ML systems.
Our MLOps approach
Production ML infrastructure should not be conceptualized merely as a model paired with an inference endpoint. Instead, it must be architected as a governed lifecycle featuring explicit control points spanning from data ingestion through post-deployment surveillance.
This implementation structures the lifecycle around six foundational pillars:
- Governed data flow: Ensuring data quality, consistency and lineage
- Tracked model lifecycle: Maintaining comprehensive versioning and audit trails
- Controlled release path: Implementing gated deployment with approval workflows
- Explainable predictions: Providing interpretable outputs for stakeholder confidence
- Continuous monitoring: Enabling proactive detection of performance degradation
- AgentOps: Leveraging intelligent agentic automation to reduce operational burden
This framework represents a paradigm shift from ad-hoc model development to systematic, production-grade ML operations.
Telco churn as the working use case
To ground the lifecycle in a tangible business context, this implementation employs a telecommunications customer churn prediction scenario.
The foundation is the IBM telco churn dataset, comprising customer demographics, service configurations, billing information and churn indicators. Within this workflow, the churn use case functions primarily as a business anchor, providing practical context while the core value proposition resides in demonstrating how models are systematically built, trained, deployed, monitored and evolved through the MLOps framework. The deliverable is a churn risk score accompanied by contextual insights to support review and retention strategies.
MLOps lifecycle in practice
The workflow architecture implements a comprehensive lifecycle that spans infrastructure provisioning and data preparation, through pipeline development and model training, to deployment and monitoring, culminating in iterative model evolution within a closed-loop system. This structure is deliberately transparent in both conceptual design and technical implementation.
The architecture's value proposition lies not in the quantity of services employed, but rather in the clarity of purpose assigned to each lifecycle stage:
- Data and feature management
The workflow initiates with data ingestion, preprocessing and feature engineering. A centralized feature store ensures consistency between the training and inference environments, substantially mitigating the risk of feature skew. - Pipeline-driven model development
Model development is orchestrated through structured pipeline stages including preprocessing, training, evaluation and registration. This approach ensures reproducibility and facilitates systematic review processes. - Governed registration and approval
Following evaluation, models progress through formal registration and approval gates before release. This governance framework strengthens version control, auditability and release discipline. - Validated deployment
Models are deployed to inference environments with integrated validation and runtime health monitoring. Explainability capabilities are embedded within the prediction pathway, ensuring users receive contextual insights rather than opaque scores. - Continuous monitoring and drift management
Post-deployment monitoring continuously evaluates input data quality, detects distributional drift and identifies violations against established baselines. Automated alerting and retraining triggers enable proactive intervention, completing the production feedback loop. - Iterative model evolution
The lifecycle extends beyond initial deployment to support continuous improvement. A secondary cycle facilitates model refinement, champion-challenger evaluation and staged rollout strategies that minimize deployment risk.
This paradigm shift reframes production ML not as a discrete deployment event, but as a continuous operational discipline.

Figure 1. End-to-end MLOps lifecycle with Agentic AI support across data, training, deployment, monitoring and model evolution
AWS services supporting the workflow
While AWS services provide essential infrastructure for the ML lifecycle, they serve as enablers rather than the focal point of this architecture.
Core services:
- Amazon S3 – Storage for datasets, model artifacts and outputs
- SageMaker Feature Store – Ensures feature consistency between training and inferences
- SageMaker Pipelines – Orchestrates end-to-end workflows
- SageMaker Experiments – Tracks and compares experimental runs
- SageMaker Model Registry – Manages model versioning and approval workflows
- SageMaker Endpoints – Serves models for inference
- SageMaker Clarify – Provides prediction explainability
- SageMaker Model Monitor – Detects drift and monitors model quality
- CloudWatch, Lambda and SNS – Enables alerting and event-driven automation
- Amazon Bedrock – Powers the agentic layer for review, triage and business interpretation
The value proposition of Agentic AI
This is where our approach diverges from conventional MLOps implementations.
Traditional MLOps delivers significant improvements in governance, release management and observability. However, substantial manual effort persists throughout the ML lifecycle. Teams continue to invest time in data quality validation, experiment comparison, training outcome review, deployment validation, drift alert interpretation and translating technical predictions into actionable business insights. The agentic layer addresses these remaining inefficiencies.
Our implementation strategically deploys AI agents at points of highest manual review burden:
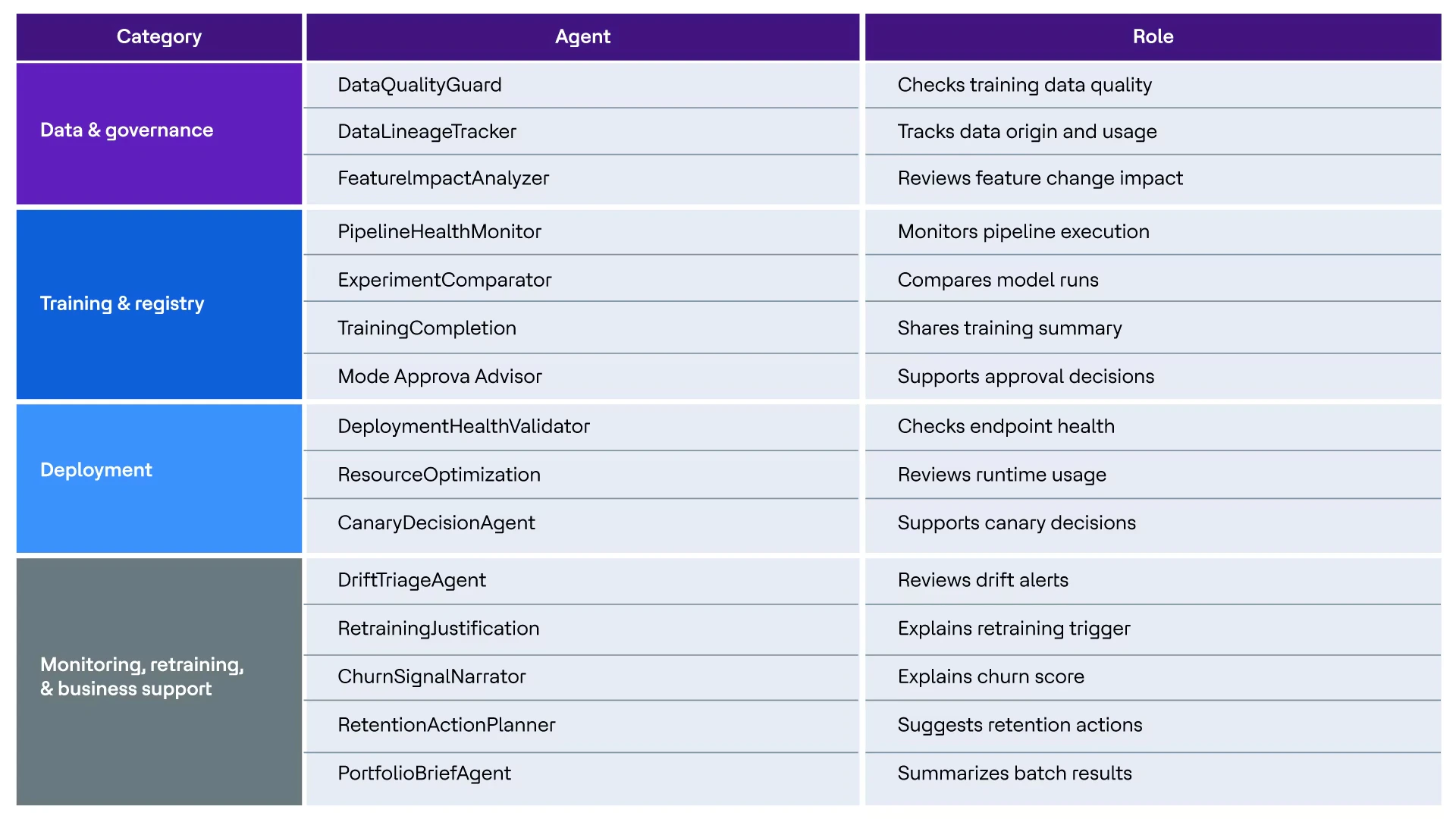
Figure 2. Agentic AI Support
The MLOps infrastructure remains intact and essential. Agents accelerate the review cycles within it.
Why this matters across personas
A key strength of this framework is its multi-stakeholder design. This is not a data science solution in isolation. It addresses the distinct needs of every role involved in the ML lifecycle.
- Data scientists require reproducible workflows for training, experiment tracking and model comparison
- ML engineers need streamlined paths from pipeline execution through deployment and monitoring
- Platform and DevOps engineers demand robust controls over runtime health, access management, logging and observability
- Business stakeholders need model outputs that are interpretable, actionable and directly applicable to decision-making
This cross-functional alignment is fundamental to the framework's value. A production ML system that serves only the ML team is not truly production-ready.
Why the second cycle matters
The inclusion of a second iteration cycle demonstrates genuine architectural maturity.
The first cycle establishes the baseline production model. The second cycle incorporates additional operational signals, conducts rigorous comparison against the baseline and executes a controlled staged rollout.
This distinction is critical because it reflects true ML maturity, not merely achieving initial deployment, but demonstrating systematic, governed improvement over time with proper validation at each stage.
Conclusion
Production ML is not defined by whether a model has been deployed. It is defined by whether that model operates within a repeatable, inspectable, governed lifecycle-one that teams can confidently execute, approve, deploy, monitor and continuously improve without relying on ad hoc manual processes. This is the fundamental problem MLOps exists to solve.
The Agentic AI layer complements this foundational lifecycle. Its purpose is not to replace MLOps discipline, but to reduce the repetitive review burden that persists even within well-structured workflows and to make technical outputs more accessible and actionable across both technical and business teams.




