

We are in era of AI. AI has significant impact on all the domains of life, either it is healthcare, business, aviation, research, transport, telecommunication, enterprise network or any other domain of life. As AI is touching day-to-day life many players are in competition to achieve the best version of it.
AI infrastructure networking requirements:
As need for AI is growing, there is also needs to add more data centers and more infrastructure to cater the demand. AI infrastructure demands high bandwidth, low-latency and lossless networks to efficiently support GPU intensive workloads and distributed AI systems. AI requires following to operate in full efficiency:
- Bandwidth and throughput: AI workload specially training large models, require networks capable of handling massive data volumes without delay. High bandwidth ensures rapid data transfer between the GPU clusters, storage system and cloud resources, preventing underutilization of the expensive hardware and reducing training time
- Low latency: Minimizing latency is also critical for real time AI applications. Low latency improves inter-GPU communication and enables faster model update.
- Lossless connectivity: AI network benefits from lossless connectivity that prevent data loss and ensure data integrity. Some of the protocols are Infiniband, ROCE and Ethernet.
GPU cluster traffic patterns:
- East-west traffic (GPU-to-GPU): This traffic involves communication between the GPUs, especially in distributed training.
- North-south traffic (data in/out): This traffic between GPU and outside world. This critical for GPU during training and inference.
- Collective communication (many-to-many): AI training often uses operations like “all-reduce” where GPU exchanges its gradient with every other GPU. This is burst kind of traffic need higher bandwidth. This is cause of in cast congestion. In cast congestion, huge burst of data arrives at single port.
- Many-to-few-to-many: On chip traffic where many processing element request data from few memory controllers.
Now to cater north-south and East-west traffic, we must consider building our network architecture according to need of modern GPUs. AI cluster require lossless network with high throughput and low latency. Also during the congestion there should be no traffic loss. Two of the most relevant option are:
- Infiniband: It was designed to connect servers and storage in clusters operating at extre-mely high data rates, commonly in the range of 100 Gbps to 400 Gbps, with minimal latency. Infiniband are expensive due to hardware requirement.
- Ethernet: Ethernet based protocol enabling high performance, lossless performance and high bandwidth. Ethernet is already deployed in traditional datacenter and mass has expertise with the technology. Already 1G, 10G, 40G and 100G are deployed in data center. But the new introduction to 400G and 800G has revolutionized the Ethernet field.
400G and 800G adoption:
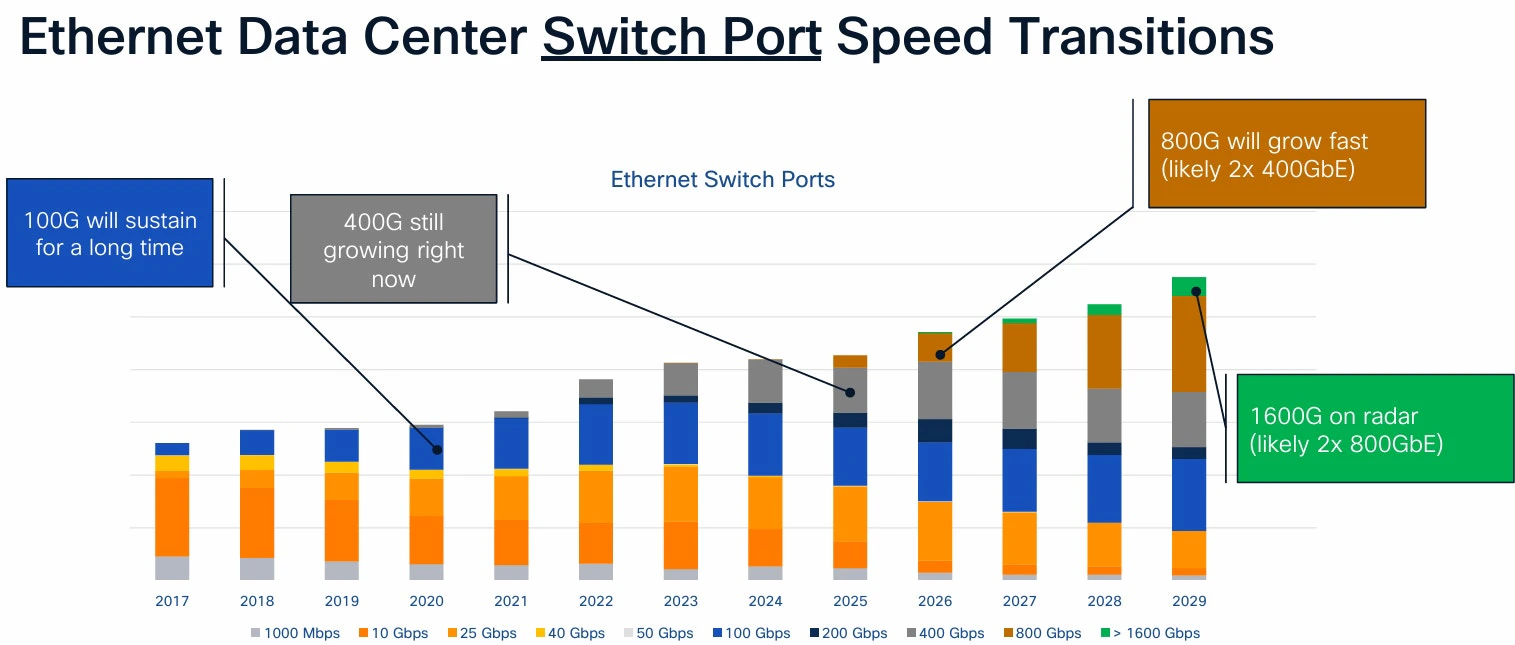
You can see how ethernet speed requirement increases year-by-year and need more speed to achieve the required AI cluster modules requirement.
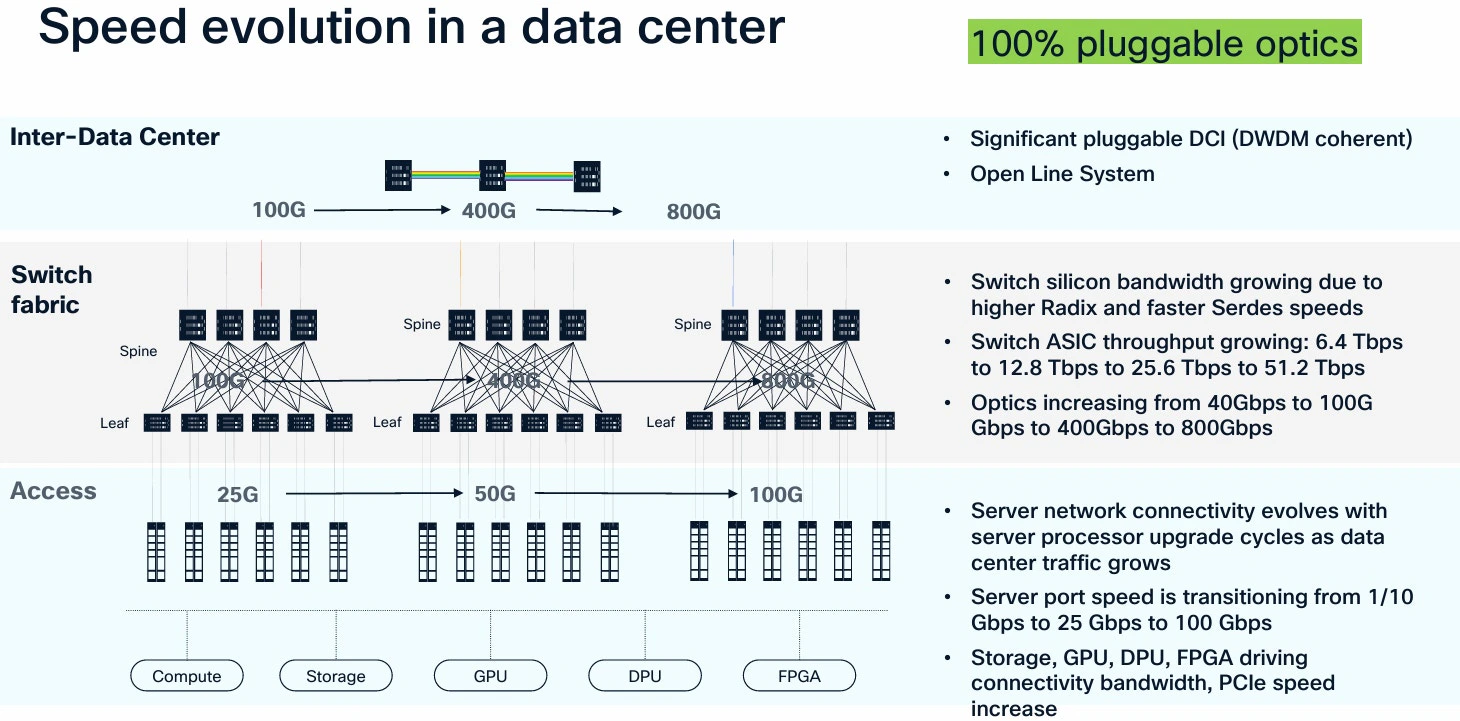
Below is an example of speed evolution in data centers:
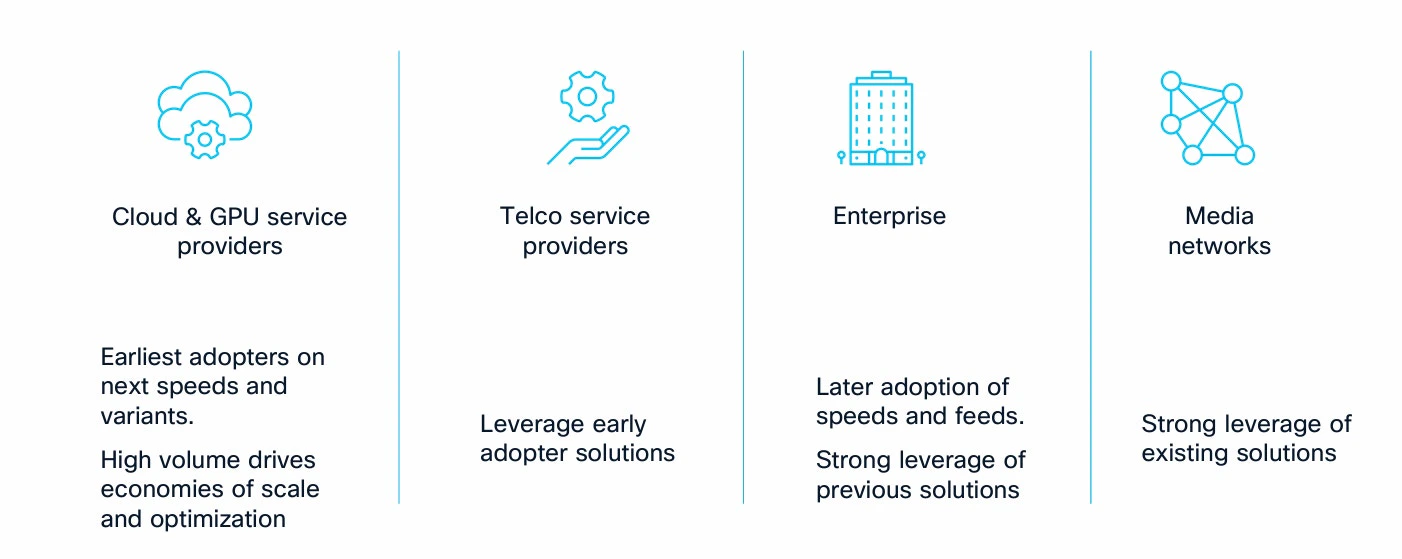
Use cases for 400G and 800G
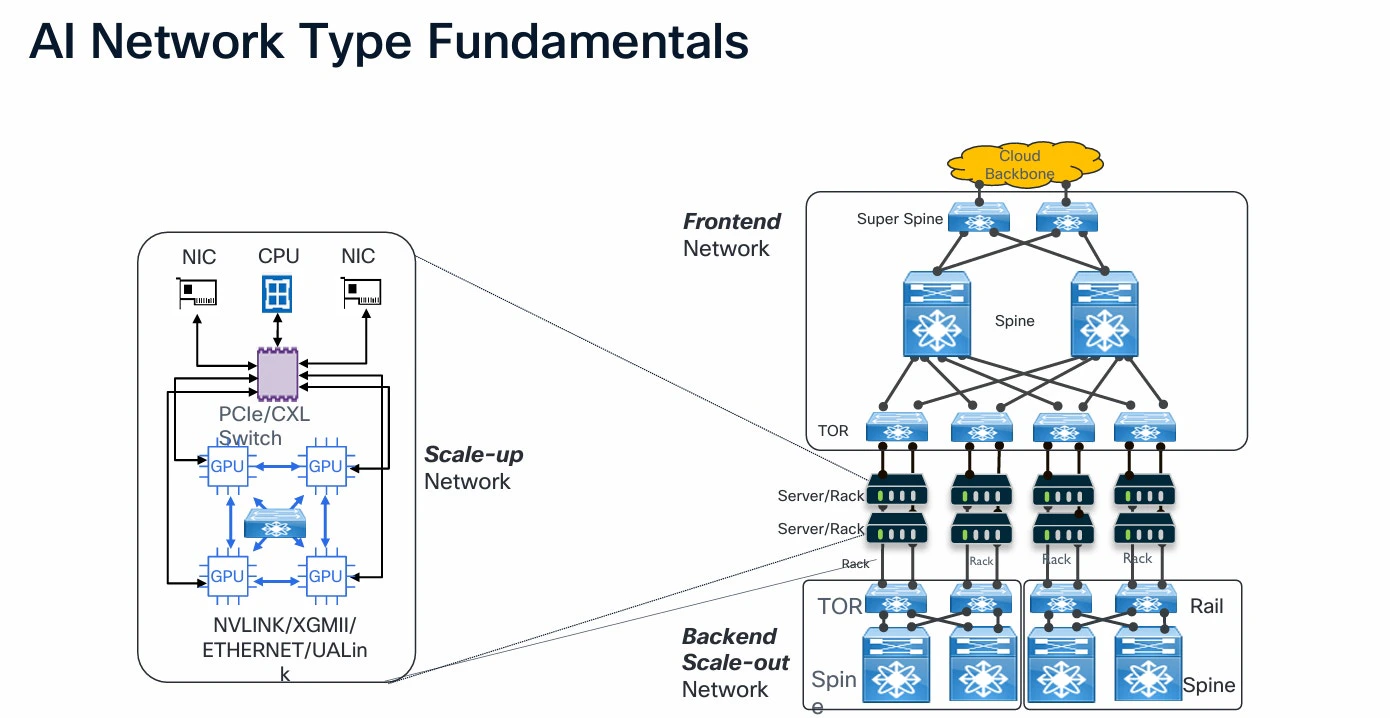
Scale-out fabric architecture:
Scale-out fabric architecture is a cornerstone of next-generation AI-enabled datacenter. By connecting nodes horizontally with a high performing fabric, it overcomes limitation of traditional scale up systems, delivering resilient and cost-effective scalability for compute and data intensive applications.
Spine and leaf architecture is traditionally used for scaling out operation in today datacenter. It features multiple spine switches (core layer) and leaf switches connecting endpoints, supporting multipoint and redundant routing. Scale-out steps can include incremental addition of leaf switches.
Congestion and latency management: AI clusters require lossless network and must provide high throughput. With use of 400G and 800G ethernet port we will be able to build the high throughput Network. Explicit Congestion Notification (ECN) and Priority Flow control (PFC) are used by the ethernet to provide more congestion control in the network for seamless connectivity.
Network visibility and telemetry: Network visibility and telemetry are critical for the managing and optimizing the network performance, especially with increasing demand of AI workloads. With 400G and 800G ethernet ports, organization can expect enhanced bandwidth, improved latency, better flow control and operation efficiency. By leveraging the capabilities of 400G and 800G port organization can ensure there network are capable of handling current demands as well as meet the future evolving needs for AI workloads.
Conclusion
The evolution of Ethernet to 400G and 800G has made it possible to build scalable, low‑latency and high‑bandwidth AI data centers. These advancements enable organizations to expand compute capacity rapidly while maintaining efficiency, performance and reliability. With proper architecture, congestion control and telemetry, next‑generation ethernet fabrics are well‑positioned to power the AI-ecosystems of the future.

