

Abstract:
Vertex AI is a Neural Architecture Search (NASNet)-based Machine Learning (ML) platform that facilitates training and deployment of ML models and AI applications. It combines data engineering, data science and ML engineering workflows, enabling teams to collaborate using a common toolset. One such toolset is BigQuery ML which is a model development service within BigQuery. It empowers SQL users to train ML models directly in BigQuery, eliminating the need to move data or worry about the underlying training infrastructure. It not only supports linear and logistic models but also more complex models like k-means clustering, matrix factorization, time series and deep neural networks among many others. Models are most useful when their metrics do not dwindle on new data. With the help of Vertex AI pipelines, the process of keeping the model metrics up to date with regular re-training can be automated. Moreover, these pipelines can operate on models trained using BigQuery ML in addition to monitoring the models to trigger re-training on metric degradation or on a fixed schedule.
Demonstration of Vertex AI and BQML pipelines for the purpose of training a model, performing inferencing, model evaluation and explanation of the prediction results. We create a Vertex AI pipeline to perform all these steps.
Introduction:
VertexAI is a platform for cloud-based ML and AI tasks offering teams to collaborate by providing robust features and streamlined workflows to automate ML and AI tasks. Two broad categories of models that can be used on the Vertex AI platform are:
- AutoML-based models
- Custom models
ML lifecycle:
Once the models are deployed, ops frameworks can be utilized to automate tasks pertaining to the ML lifecycle. A typical ML workflow contains below steps:
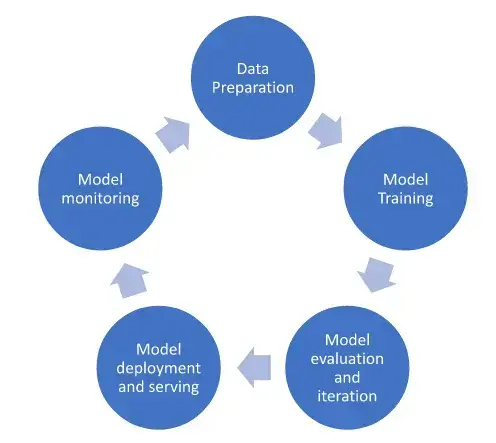
Google Cloud Platform (GCP) provides tools to perform all the above operations using multiple services.
Data preparation:
Workbench Notebooks is a tool which assists users in leveraging multitude of Python libraries to perform the task of data preparation. Services like DataFlow can be employed to perform Exploratory Data Analysis (EDA) on streaming data. While dealing with data on an enterprise scale, Dataproc comes into play, enabling the use of Big Data tools like Spark to perform this EDA and other data preparation steps. For automated EDA, tools like DataPrep can be put to use.
Model training:
For the model training task, various alternatives can be used. AutoML can be used for the ML model training without code on three types of datasets — tabular, image and video. Furthermore, AutoML steps are available to be called from Kubeflow pipelines using a library called google-cloud-pipeline-components. Another alternative to perform this task is to conduct the training in a notebook within the Workbench Notebooks service. There is also an option to run training tasks in a docker container and launch it as part of the Kubeflow pipeline custom training task. Similar training is also possible using custom training based on the TFX framework. Vertex AI is compatible with all the possible libraries out there and has support for custom hyperparameter training jobs. Hence, there is no limitation on the framework or library to use for custom training. It could be done in Pytorch, Tensorflow, Scikit-learn, Caffe and many other libraries. Tensorboard can be utilized to visualize model parameters, while Vizier facilitates training hyperparameters for custom models. Finally, after the completion of training models, they can be uploaded for inferencing in the Model registry.
Model evaluation and iteration:
Once the model is built, various model parameters can be trained by employing services like experiments and metadata. These services help in monitoring various experiments conducted on the model and the various metrics gathered from each of those experiments. These evaluations can also be performed as part of ML Ops pipelines to track these parameters in long ML workflows.
Model deployment and serving
Once the model is trained sufficiently, it can be hosted for batch and online predictions. To make this work, either prebuilt containers can be leveraged with standard environments and libraries, or docker containers can be provided where environments and libraries are customizable based on specific ML tasks deemed necessary by the user. The batch predictions can be obtained from a service known as Batch Prediction and online predictions can be made either with the help of a Vertex AI pipeline or any other service like Dataflow that can make a REST API call to the hosted model in the Endpoints in Vertex AI. Vertex AI also provides optimized Tensorflow runtime that has lower latency and lower cost than open source prebuilt Tensorflow containers. For data specific to tabular models, Feature Store service can be employed to provide access to features that can be collected, improved and updated over various timeframes. These features can be used to train a model based on the best available features. Explainable AI can also be used to attribute the significance of a particular feature in coming up with predictions. An explainable AI can be used to find mislabeled data in the input dataset. In addition to this, models from Bigquery ML can be exported into Vertex AI and vice versa — albeit there might be certain limitations on frameworks and model sizes.
Model monitoring:
In model monitoring, continuous monitoring of an ML model is done to ensure that it is currently properly trained and that the results it produces are under acceptable limits.
The service basically calculates skew and drift and sends alerts if the values differ too far from expectations.
Problem statement:
The dataset includes information about ~73,000 scrabble games played by three bots on Woogles.io: BetterBot (beginner), STEEBot (intermediate) and HastyBot (advanced). The games are between the bots and their opponents, who are regular registered users. Metadata about the games is utilized as well as turns in each game (i.e., players' racks and where and what they played, AKA gameplay) to predict the rating of the human opponents in the test set (master_test Bigquery table). Model will be trained on gameplay data from one set of human opponents to make predictions about a different set of human opponents in the test set.
There is metadata for each game, gameplay data about turns played by each player in each game and final scores and ratings before a given game was played for each player in each game (master_test, master_train Bigquery table).
Here is an example of a game played on woogles.io: woogles.io/game. Use the "Examine" button to replay the game turn-by-turn.
The task is to predict what the rating of the human player was in the master_test Bigquery table before the given game was played.
Design:
The data is spread across various tables such as turns, games, tests and trains. Since the BQML models cannot themselves perform joins on the tables and perform learning, tables must be created with master data.
Once the data is available in master_train and master_test tables to train and test, BQML models should be explored to perform the regression step. Each of these models will train on the master train data columns and regress the human player rating based on the game steps and outcomes. Six possible BQML models will be trained with hyperparameter tuning. Once the best model is available, the subsequent steps will be performed.
In the following steps, a Vertex AI pipeline will be created to perform the final training and evaluation on the chosen model repetitively. In this pipeline, the chosen BQML model will be trained on the data and perform regression steps on the test data.
Approach:
- Download data from Kaggle with this command: kaggle competitions download -c scrabble-player-rating
- Upload the data files to GCS: gsutil cp *.csv gs://bucket1/data/
- Load data into Bigquery using the following commands executed on the console:
- bq load –autodetect scrabble.turns gs://bucket1/data/turns.csv
- bq load –autodetect scrabble.games gs://bucket1/data/games.csv
- bq load –autodetect scrabble.train gs://bucket1/data/train.csv
- bq load –autodetect scrabble.test gs://bucket1/data/test.csv
- bq load –autodetect scrabble.sample_submissions gs://bucket1/data/sample_submissions.csv
-
Perform data cleaning and join the various tables into master_train and master_test tables using the following SQL queries:
TABLE scrabble.train_processed CREATE TABLE scrabble.master_train CREATE TABLE scrabble.test_processed CREATE TABLE scrabble.master_test -
Create various regression BQML models:
LINEAR REGRESSION MODEL CREATE MODELscrabble.linreg2 BOOSTED TREE REGRESSION MODEL CREATE MODEL scrabble.btreg RANDOM FOREST REGRESSOR CREATE MODEL scrabble.rfreg DEEP NEURAL NETWORK REGRESSOR CREATE MODEL scrabble.dnnreg WIDE AND DEEP NEURAL NETWORK REGRESSOR CREATE MODEL scrabble.wdnreg AUTOML REGRESSOR CREATE MODEL scrabble.autoreg
After creating the above models and comparing the results obtained from them, it could be concluded that wide and deep neural networks are giving the best results in predicting the ratings of the human player before they played against the Bot as described in the test dataset.
So, the below MLOps pipeline was developed to train, evaluate and explain the predictions of a BQML model with the help of data in the master train and master test tables.
Vertex AI pipeline code:
| # Module imports # Global variable declaration # Declaration of the pipeline block containing a method containing the pipeline execution code and annotation to mark the method as a pipeline block # First step of the Vertex AI pipeline. This step will create a BQML model in the Bigquery. # Second step in the Vertex AI pipeline. This step will perform prediction on the model produced in the previous step of Vertex AI. # Third step in the Vertex AI pipeline is parallel to the second step. This step will perform the evaluation of the BQML model produced in the first step and generate model evaluations. # Fourth step in the Vertex AI pipeline. This will run parallel to the second and third steps and will generate an Explain Model to perform attributions of features to the results produced by the BQML pipeline. # Compile the pipeline block into a JSON specification. This specification can be fed to the Vertex AI platform to generate an executable DAG. # Initialize the AI Platform SDK # Prepare the pipeline job object to run the job in the Vertex AI # Run the pipeline job |
The diagram of the generated DAG for the pipeline defined above:
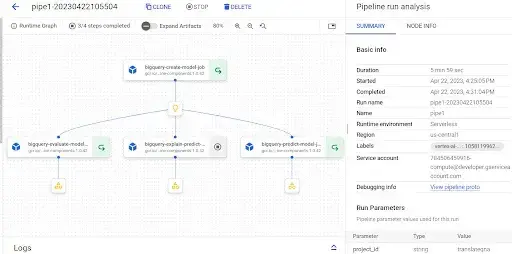
The DAG above shows four steps in the pipeline. The first step will create a BQML model. The second step will generate evaluation metrics of the BQML model generated. The third step will generate evaluations of the data on the trained model. The fourth step will generate an explanation model to generate feature attributions for the predictions generated.
The evaluation metrics generated can be seen in the metadata section of the Vertex AI. The predictions can be seen in the BigQuery table specified in the configuration of the pipeline.
Data points:
- The evaluation metrics generated in the Vertex AI pipeline:
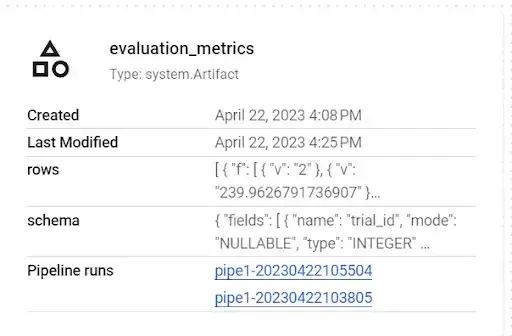
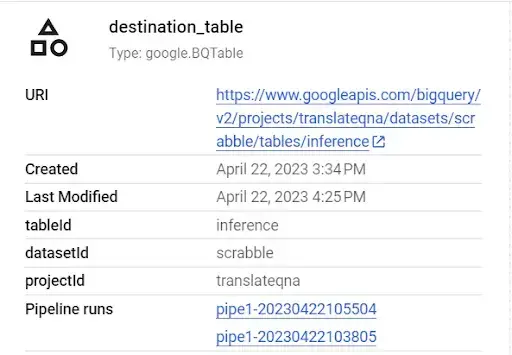
- Destination table artifact generated in the Vertex AI pipeline:
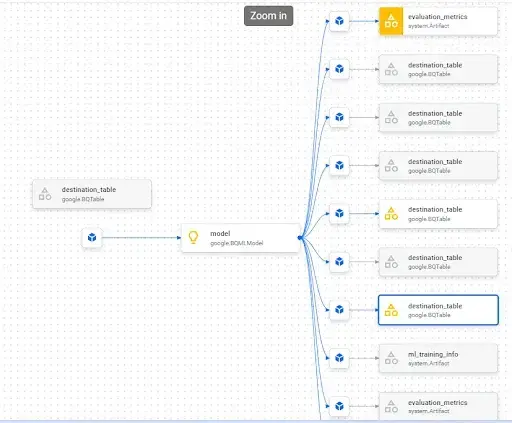
- Metadata Lineage generated in the Metadata section of Vertex AI:
- JSON of model artifact generated:
{ ... "instanceSchemaTitle": "google.BQMLModel", ... "schemaTitle": "google.BQMLModel", "schemaVersion": "0.0.1", } -
Predictions generated by the pipeline:
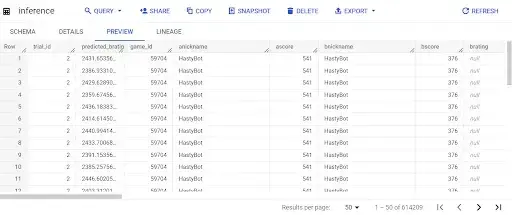
The inference is given in the ”predicted_brating” column of the inference table.
Summary:
As the next step, all the BQML models can be trained in the Vertex AI pipeline and model selection can be performed in the pipeline itself, ensuring all types of variations in the data are captured within the best model, thus providing the best possible regression results. Here the Vertex AI pipeline for the BQML model could be demonstrated. Other possible pipelines could be made with the AutoML model, TensorFlow, PyTorch, Caffe and other framework models. Additionally, the predictions can be seen written to a BigQuery table and the artifacts were present in the Vertex AI.
References:
- https://google-cloud-pipeline-components.readthedocs.io/en/google-cloud-pipeline-components-1.0.40/
- https://cloud.google.com/vertex-ai/docs/pipelines/introduction
- https://cloud.google.com/bigquery-ml/docs/create-machine-learning-model
- https://cloud.google.com/bigquery/docs/reference/libraries-overview
