
Présentation
Snowflake est actuellement le leader du marché pour permettre le stockage, le traitement et des solutions analytiques flexibles des données en fournissant une plateforme de données avancée comme service autogéré.
En général, Snowflake produit des données bien regroupées dans les tables en utilisant le regroupement naturel dans l’ordre où les données sont ingérées ; toutefois, avec le temps, principalement lorsque des opérations DML (Data Manipulation Language) sont effectuées sur des grandes tables, les données de certaines lignes de la table peuvent ne plus être regroupées de façon optimale selon les dimensions souhaitées.
Quand l’utiliser ?
Lorsque les performances des requêtes se dégradent avec le temps pour de grandes tables en raison d’une réduction ou absence de partitionnement, le regroupement de la table permet de réduire la lecture des micro-partitions et d’améliorer les performances de requête. Utiliser le service de regroupement de Snowflake peut s’avérer très coûteux, en particulier lorsqu’il y a de nombreuses opérations DML (Data Manipulation Language) sur la table concernée. Pour optimiser l’utilisation des crédits liés au service de regroupement, nous suggérons d’implémenter un regroupement manuel via l’exécution d’une procédure stockée Snowflake, comme décrit ci-dessous.
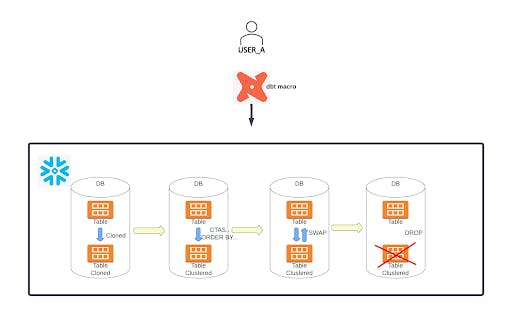
Pour améliorer le regroupement des micro-partitions sous-jacentes de la table, une procédure stockée enveloppée par une macro dbt est créée afin de trier les lignes selon les colonnes clés de la table, puis de les réinsérer dans la table. Cela permet d’éviter l’utilisation du coûteux service de regroupement automatique.
Avantages pour l’entreprise
Dans le cadre des mesures d’amélioration des performances des requêtes, le regroupement manuel d’une table Snowflake sur la base des clés de regroupement fournies a été introduit. Il s’agit d’une alternative pour regrouper rapidement les données afin d’éviter l’utilisation du coûteux service de regroupement automatique de Snowflake, qui est une fonctionnalité sans serveur (entièrement gérée par Snowflake) s’exécutant en continu en arrière-plan, générant des coûts de calcul hors du contrôle de l’utilisateur. Lors du traitement de tables fréquemment mises à jour, le service de regroupement automatique peut devenir très coûteux en termes de consommation de crédits. Malheureusement, les surveillants de ressources ne permettent pas de gérer les dépenses associées au Warehouse de regroupement automatique. Un regroupement manuel, souvent appelé regroupement manuel, peut aider à contrôler la consommation de crédits Snowflake grâce à un regroupement optimal et ponctuel des données non regroupées, en fonction de la dégradation des performances des requêtes.
Opérations impliquées
La fonctionnalité de regroupement manuel a été réalisée par le biais d’une procédure stockée Snowflake, qui peut être appelée depuis une macro dbt avec les paramètres requis : nom de la table, clés de regroupement et nom du Warehouse virtuel (facultatif). Le processus implique principalement les étapes suivantes :
- Il assigne le WAREHOUSE transmis comme paramètre à la macro. Si rien n’est transmis, un warehouse virtuel XL est assigné selon la logique ci-dessous.
- Il crée ensuite une table de sauvegarde en clonant la table à regrouper. Puis, il déclenche une commande CTAS (CREATE TABLE AS SELECT) pour créer une table regroupée, triée selon les clés de regroupement fournies.
- Une fois l’étape précédente réussie, la commande « ALTER TABLE SWAP » est utilisée pour renommer la table triée avec les données vers la table d’origine.
- Il supprime la table intermédiaire regroupée après le succès de l’étape précédente.
- Il trouve et supprime toutes les tables clonées de la base de données sauf la dernière table clonée.

Améliorez la performance des requêtes et l’efficacité des coûts grâce au regroupement manuel dans Snowflake
Conclusion
Cette fonctionnalité peut constituer une solution entièrement basée sur Snowflake où la procédure stockée peut être exécutée de façon programmée dans les tâches ou, comme illustré ici, orchestrée via le dbt Cloud Scheduler enveloppant les procédures stockées par une macro dbt. Si d’autres outils ETL/ELT sont utilisés dans votre projet, le même outil peut servir à appeler les procédures stockées Snowflake pour effectuer le regroupement manuel. Ce regroupement manuel peut aussi être intégré à la re-regroupement Snowflake pour garder les données regroupées de manière opportune dans le cadre du processus de semi-regroupement.
Annexe
Veuillez noter qu’il est conseillé d’exécuter le processus de regroupement avec le rôle approprié (pour toute table contenant des données masquées). Dans les cas où le rôle ne dispose pas des privilèges requis pour accéder aux données réelles des colonnes masquées, la création d’une table regroupée avec les valeurs masquées originales est potentiellement risquée. Il devient alors impossible de faire correspondre ces valeurs avec leurs équivalents non masqués, ce qui aboutit à une corruption des données.
