
Overview
Snowflake is currently the market leader for enabling data storage, processing, and flexible analytical solutions by providing an advanced data platform as a self-managed service.
In general, Snowflake produces well-clustered data in tables utilizing natural clustering in the order as the data is ingested; however, over time, mainly as DML (Data Manipulation Language) occurs on extensive tables, the data in some table rows might no longer cluster optimally on desired dimensions.
When to Use it?
When the query performance degrades over time for extensive tables for less to no-partition pruning, clustering the table is helpful to reduce the scanning of micro-partitions and improve the query performance. Using Snowflake's clustering service can be very expensive, specifically when there are widespread DML (Data Manipulation Language) operations on the concerned table. To optimize credit usage for the clustering service, we suggest implementing manual clustering through the execution of a Snowflake stored procedure, as described below.
To improve the clustering of the underlying table micro-partitions, a store procedure wrapped up by a dbt macro is created to sort rows on key table columns and re-insert them into the table. This has been created to avoid using expensive automatic clustering services.
Business Benefits
As part of the query performance improvement measures, manual clustering of a Snowflake table based on the supplied clustering keys has been introduced. This is an alternative way of getting the data clustered promptly to avoid using the expensive Automatic Clustering service of Snowflake, which is a serverless feature (completely managed by Snowflake) running continuously under the hood, incurring compute cost which is beyond the control of the user. When dealing with frequently updated tables, the Automatic Clustering service can become quite costly in terms of credit consumption. Unfortunately, resource monitors can’t be utilized to manage the expenses associated with the Automatic Clustering Warehouse. A manual clustering, often termed as manual clustering, can help control the Snowflake credit consumption by optimal and need-based clustering of un-clustered data in a timely manner depending upon the degradation of the query performance.
Operations Involved
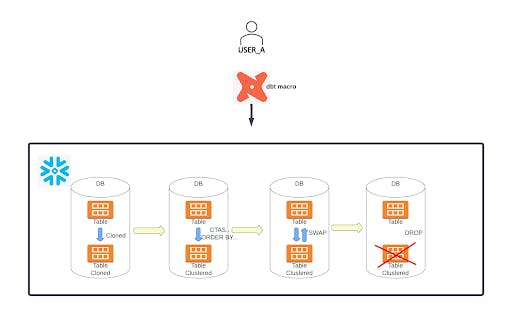
The manual clustering feature has been achieved by a Snowflake Stored Proc, which can be called from a dbt macro with the supplied parameters–table name, clustering keys and the Virtual Warehouse name (optional). The process mainly involves the following steps:
- It assigns the WAREHOUSE as passed by the input parameter of the macro. If nothing is passed, it assigns a XL virtual warehouse as per the logic below.
- It then creates a backup table by cloning the table to be clustered. Then it triggers a CTAS (CREATE TABLE AS SELECT) command to create a clustered table sorted by the cluster keys provided.
- Once the above step is successful, it triggers the “ALTER TABLE SWAP" command to have the table with sorted data renamed to the original table.
- It drops the intermediate clustered table after the above step is successful.
- It finds and drops all the cloned tables in the database except the latest cloned table.

Conclusion
This feature can be a fully Snowflake-based solution where the store procedure can be run in a schedule in tasks or, as depicted here, orchestrated through dbt Cloud Scheduler wrapping the stored procedures by a dbt macro. If any other ETL/ELT tools are used in your project, the same tool can be used to call the Snowflake stored procedures to perform the manual clustering. This manual clustering can also be integrated with Snowflake re-clustering to keep the data clustered in a timely manner as part of the semi-clustering process.
Appendix
Please note that running the clustering process with the proper role is advisable (for any tables with masked data). In scenarios where the role lacks the necessary privileges to access the actual data for masked columns, creating a clustered table with the original masked values is potentially risky. As a result, it becomes impossible to map these values back to their unmasked counterparts, leading to data corruption.
