

Résumé :
Vertex AI est une plateforme d’apprentissage automatique (ML) basée sur la recherche d’architecture neuronale (NASNet), qui facilite l’entraînement et le déploiement de modèles ML et d’applications IA. Elle combine l’ingénierie des données, la science des données et les flux de travail en ingénierie ML, permettant aux équipes de collaborer à l’aide d’une boîte à outils commune. L’un de ces outils est BigQuery ML, qui est un service de développement de modèles au sein de BigQuery. Il permet aux utilisateurs SQL de former des modèles ML directement dans BigQuery, éliminant le besoin de déplacer des données ou de se soucier de l’infrastructure d’entraînement sous-jacente. Il prend en charge non seulement les modèles linéaires et logistiques, mais aussi des modèles plus complexes comme le clustering k-means, la factorisation matricielle, les séries temporelles et les réseaux neuronaux profonds, parmi beaucoup d’autres. Les modèles sont les plus utiles lorsque leurs métriques ne diminuent pas sur de nouvelles données. Grâce aux pipelines Vertex AI, le processus de mise à jour automatique des métriques des modèles avec des réentraînements réguliers peut être automatisé. De plus, ces pipelines peuvent fonctionner sur des modèles entraînés à l’aide de BigQuery ML en plus de surveiller les modèles afin de déclencher un réentraînement en cas de dégradation des métriques ou selon un calendrier fixe.

Démonstration des pipelines Vertex AI et BQML dans le but d’entraîner un modèle, effectuer des inférences, évaluer le modèle et expliquer les résultats des prédictions. Nous créons un pipeline Vertex AI pour réaliser toutes ces étapes.
Introduction :
VertexAI est une plateforme pour des tâches ML et IA infonuagiques offrant aux équipes des fonctionnalités robustes et des flux de travail simplifiés afin d’automatiser les tâches ML et IA. Deux grandes catégories de modèles peuvent être utilisées sur la plateforme Vertex AI :
- Modèles basés sur AutoML
- Modèles personnalisés
Cycle de vie du ML :
Une fois les modèles déployés, des cadres ops peuvent être utilisés pour automatiser les tâches associées au cycle de vie du ML. Un flux de travail ML typique comprend les étapes suivantes :
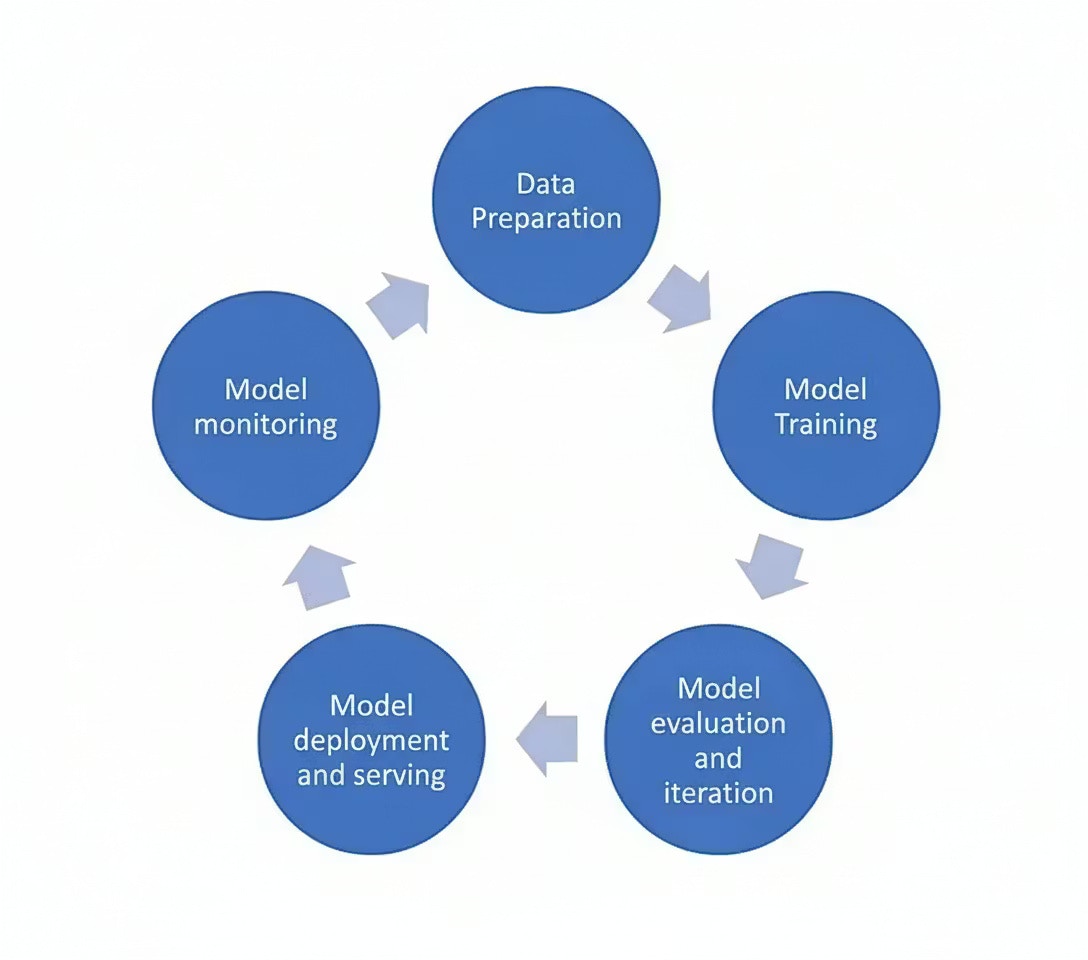
Google Cloud Platform (GCP) fournit des outils pour effectuer toutes les opérations ci-dessus à l’aide de multiples services.
Préparation des données :
Workbench Notebooks est un outil qui aide les utilisateurs à exploiter de nombreuses bibliothèques Python pour effectuer la préparation des données. Des services comme DataFlow peuvent être utilisés pour effectuer une analyse exploratoire des données (EDA) sur des données en continu. Lorsqu’on traite de données à l’échelle d’une entreprise, Dataproc entre en jeu, permettant l’utilisation d’outils Big Data comme Spark pour réaliser cette EDA et d’autres étapes de préparation des données. Pour une EDA automatisée, des outils comme DataPrep peuvent être utilisés.
Entraînement du modèle :
Pour la tâche d’entraînement du modèle, plusieurs alternatives sont possibles. AutoML peut être utilisé pour entraîner le modèle ML sans code sur trois types de jeux de données — tabulaire, image et vidéo. De plus, des étapes AutoML sont disponibles à appeler depuis des pipelines Kubeflow grâce à une bibliothèque appelée google-cloud-pipeline-components. Une autre alternative est de procéder à l’entraînement dans un notebook du service Workbench Notebooks. Une option existe aussi pour exécuter des tâches d’entraînement dans un conteneur docker et le lancer comme une tâche d’entraînement personnalisée dans le pipeline Kubeflow. Un entraînement similaire est également possible avec l’entraînement personnalisé basé sur le cadre TFX. Vertex AI est compatible avec toutes les bibliothèques existantes et prend en charge les tâches personnalisées d’entraînement d’hyperparamètres. Il n’y a donc aucune limitation quant au cadre ou à la bibliothèque à utiliser pour l’entraînement personnalisé. Cela peut se faire dans Pytorch, Tensorflow, Scikit-learn, Caffe et bien d’autres bibliothèques. Tensorboard peut être utilisé pour visualiser les paramètres du modèle, tandis que Vizier facilite l’ajustement des hyperparamètres pour des modèles personnalisés. Enfin, après l’entraînement des modèles, ils peuvent être téléversés pour faire de l’inférence dans le registre des modèles.
Évaluation et itération du modèle :
Une fois le modèle construit, divers paramètres du modèle peuvent être entraînés en utilisant des services comme experiments et metadata. Ces services permettent de surveiller diverses expériences menées sur le modèle et les diverses métriques recueillies lors de chacune de ces expériences. Ces évaluations peuvent aussi être réalisées dans le cadre des pipelines ML Ops afin de suivre ces paramètres dans des flux de travail ML longs.
Déploiement et service du modèle
Lorsque le modèle est suffisamment entraîné, il peut être hébergé pour des prédictions par lot et en ligne. Pour ce faire, soit des conteneurs préconfigurés peuvent être utilisés avec des environnements et bibliothèques standards, soit des conteneurs docker peuvent être fournis où les environnements et bibliothèques sont personnalisables selon les tâches ML spécifiques jugées nécessaires par l’utilisateur. Les prédictions par lot peuvent être obtenues à partir d’un service appelé Prédiction par lot et les prédictions en ligne peuvent être effectuées soit à l’aide d’un pipeline Vertex AI, soit à l’aide de tout autre service comme Dataflow qui peut effectuer un appel d’API REST vers le modèle hébergé dans les points de terminaison de Vertex AI. Vertex AI offre également un runtime Tensorflow optimisé avec une latence plus faible et un coût moindre que les conteneurs Tensorflow open source préconfigurés. Pour les données spécifiques aux modèles tabulaires, le service Feature Store peut être utilisé afin d’accéder à des caractéristiques qui peuvent être collectées, améliorées et mises à jour à divers moments. Ces caractéristiques peuvent servir à entraîner un modèle basé sur les meilleures caractéristiques disponibles. L’IA explicable peut également être utilisée pour attribuer l’importance d’une caractéristique donnée dans la génération des prédictions. Une IA explicable peut ainsi servir à détecter les données mal étiquetées dans l’ensemble de données d’entrée. De plus, les modèles de Bigquery ML peuvent être exportés vers Vertex AI, et inversement — bien qu’il puisse exister certaines limitations sur les cadres et les tailles de modèles.
Surveillance du modèle :
En surveillance de modèle, une surveillance continue d’un modèle ML est effectuée afin de s’assurer qu’il est actuellement bien entraîné et que les résultats générés sont dans les limites acceptables.
Le service calcule essentiellement l’écart et la dérive, et envoie des alertes si les valeurs s’éloignent trop des attentes.
Énoncé du problème :
Le jeu de données comprend des informations sur environ 73 000 parties de Scrabble jouées par trois robots sur Woogles.io : BetterBot (débutant), STEEBot (intermédiaire) et HastyBot (avancé). Les parties se jouent entre les robots et leurs adversaires, qui sont des utilisateurs réguliers inscrits. Les métadonnées sur les parties sont utilisées ainsi que les coups dans chaque partie (c’est-à-dire, les chevalets des joueurs et où/qu’est-ce qu’ils ont joué, aussi appelé gameplay) pour prédire la cote des adversaires humains dans l’ensemble de test (table Bigquery master_test). Le modèle sera entraîné sur les données de jeu d’un ensemble d’adversaires humains afin de faire des prédictions sur un ensemble différent d’adversaires humains dans l’ensemble de test.
On dispose de métadonnées pour chaque partie, de données de jeu concernant les coups joués par chaque joueur dans chaque partie, ainsi que des scores finaux et cotes avant qu’une partie ne soit jouée pour chaque joueur dans chaque partie (tables Bigquery master_test, master_train).
Voici un exemple d’une partie jouée sur woogles.io : woogles.io/game. Utilisez le bouton « Examiner » pour rejouer la partie tour par tour.
La tâche consiste à prédire quelle était la cote du joueur humain dans la table master_test de Bigquery avant la partie donnée.
Conception :
Les données sont réparties dans différentes tables telles que turns, games, tests et trains. Comme les modèles BQML ne peuvent pas effectuer eux-mêmes des jointures sur les tables et apprendre, il faut créer des tables avec des données maîtres.
Une fois les données disponibles dans les tables master_train et master_test, il convient d’explorer les modèles BQML afin de réaliser l’étape de régression. Chacun de ces modèles sera entraîné sur les colonnes de données master_train et effectuera la régression de la cote du joueur humain selon les étapes et les résultats des parties. Six modèles BQML possibles seront entraînés avec réglage d’hyperparamètres. Une fois le meilleur modèle disponible, les étapes suivantes pourront être réalisées.
Dans les étapes suivantes, un pipeline Vertex AI sera créé pour réaliser l’entraînement final et l’évaluation sur le modèle choisi, de façon répétée. Dans ce pipeline, le modèle BQML choisi sera entraîné sur les données et exécutera des étapes de régression sur les données de test.
Démarche :
- Télécharger les données depuis Kaggle avec cette commande : kaggle competitions download -c scrabble-player-rating
- Importer les fichiers de données sur GCS : gsutil cp *.csv gs://bucket1/data/
- Charger les données dans Bigquery avec les commandes suivantes exécutées sur la console :
- bq load –autodetect scrabble.turns gs://bucket1/data/turns.csv
- bq load –autodetect scrabble.games gs://bucket1/data/games.csv
- bq load –autodetect scrabble.train gs://bucket1/data/train.csv
- bq load –autodetect scrabble.test gs://bucket1/data/test.csv
- bq load –autodetect scrabble.sample_submissions gs://bucket1/data/sample_submissions.csv
Effectuer le nettoyage des données et joindre les différentes tables dans master_train et master_test à l’aide des requêtes SQL suivantes :
TABLE scrabble.train_processed CREATE TABLE scrabble.master_train CREATE TABLE scrabble.test_processed CREATE TABLE scrabble.master_test Créer divers modèles de régression BQML :
MODÈLE DE RÉGRESSION LINÉAIRE CREATE MODELscrabble.linreg2 MODÈLE DE RÉGRESSION PAR ARBRE BOOSTÉ CREATE MODEL scrabble.btreg RÉGRESSSEUR FORÊT ALÉATOIRE CREATE MODEL scrabble.rfreg RÉGRESSEUR PAR RÉSEAU DE NEURONES PROFOND CREATE MODEL scrabble.dnnreg RÉGRESSEUR PAR RÉSEAU DE NEURONES LARGE ET PROFOND CREATE MODEL scrabble.wdnreg RÉGRESSEUR AUTOML CREATE MODEL scrabble.autoreg
Après avoir créé les modèles ci-dessus et comparé les résultats obtenus, on a pu conclure que les réseaux de neurones larges et profonds donnaient les meilleurs résultats pour prédire les cotes du joueur humain avant qu’il n’affronte le Bot comme décrit dans l’ensemble de test.
Le pipeline MLOps ci-dessous a donc été développé pour entraîner, évaluer et expliquer les prédictions d’un modèle BQML à l’aide des données des tables master_train et master_test.
Code du pipeline Vertex AI :
| # Importation des modules # Déclaration de variables globales # Déclaration du bloc pipeline contenant une méthode qui contient le code d’exécution du pipeline et annotation pour marquer la méthode comme bloc de pipeline # Première étape du pipeline Vertex AI. Cette étape créera un modèle BQML dans Bigquery. # Deuxième étape du pipeline Vertex AI. Cette étape effectuera la prédiction sur le modèle produit dans l’étape précédente de Vertex AI. # Troisième étape du pipeline Vertex AI en parallèle avec la seconde. Elle effectuera l’évaluation du modèle BQML produit à la première étape et générera les évaluations du modèle. # Quatrième étape du pipeline Vertex AI. Cette étape fonctionnera en parallèle de la seconde et de la troisième et générera un modèle d’explication pour attribuer les caractéristiques aux résultats produits par le pipeline BQML. # Compiler le bloc pipeline en une spécification JSON. Cette spécification peut être transmise à la plateforme Vertex AI pour générer un DAG exécutable. # Initialiser le SDK AI Platform # Préparer l’objet job pipeline pour lancer le job dans Vertex AI # Exécuter le job pipeline |
Le diagramme du DAG généré pour le pipeline défini ci-dessus :
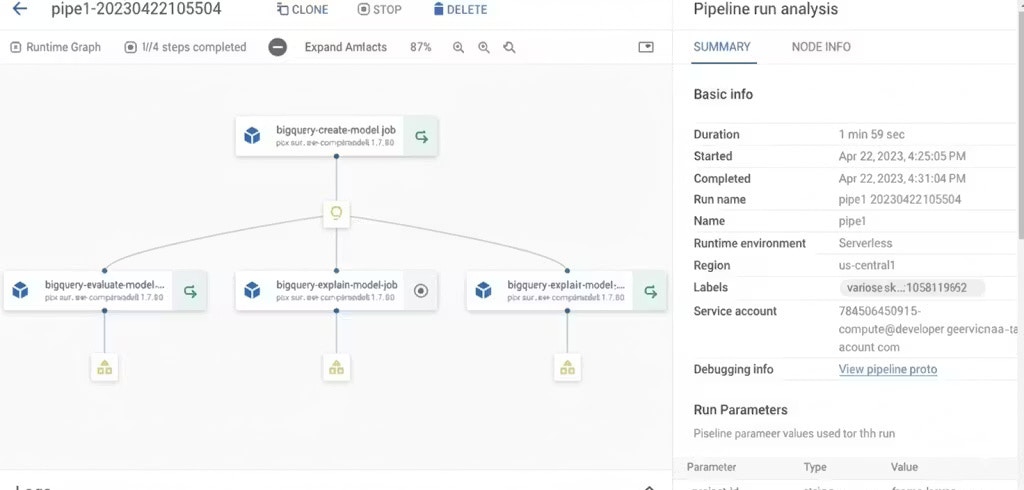
Le DAG ci-dessus montre quatre étapes dans le pipeline. La première étape créera un modèle BQML. La deuxième générera les métriques d’évaluation du modèle BQML généré. La troisième générera les évaluations des données sur le modèle entraîné. La quatrième générera un modèle d’explication pour produire les attributions de caractéristiques pour les prédictions générées.
Les métriques d’évaluation générées peuvent être consultées dans la section des métadonnées de Vertex AI. Les prédictions sont visibles dans la table BigQuery spécifiée dans la configuration du pipeline.
Points de données :
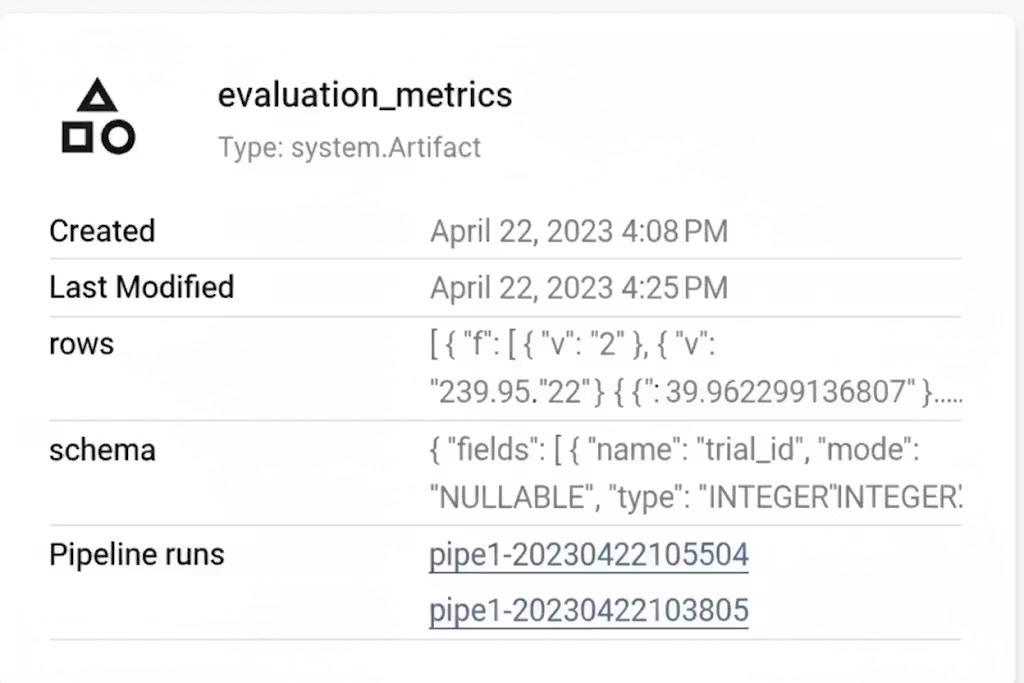
- Les métriques d’évaluation générées dans le pipeline Vertex AI :
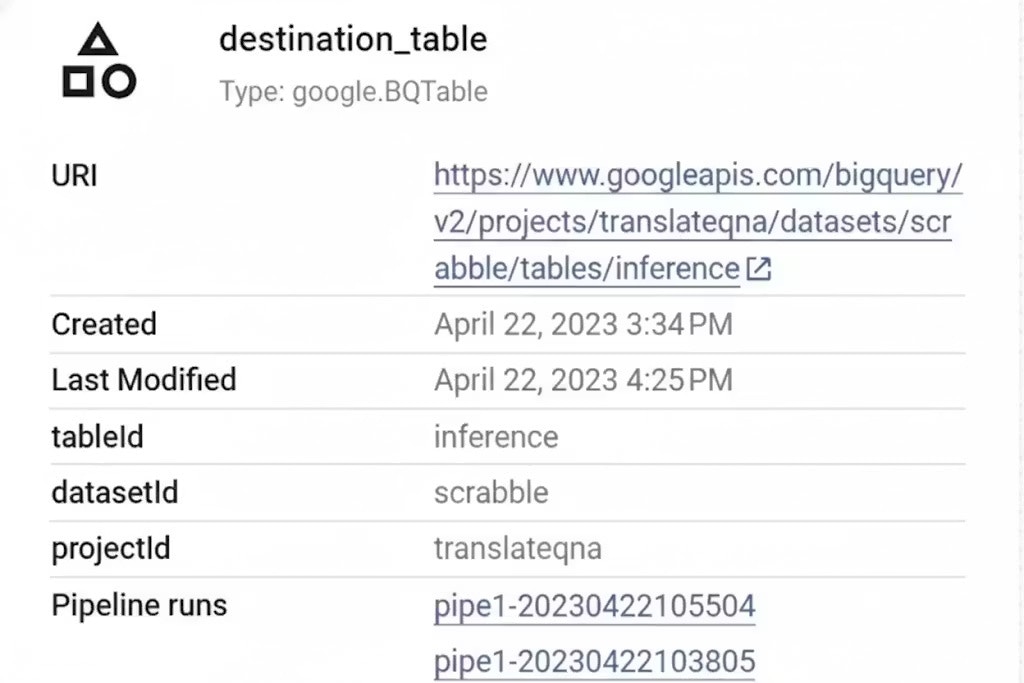
- Artefact de table de destination généré dans le pipeline Vertex AI :
- Lignée des métadonnées générée dans la section Métadonnées de Vertex AI :
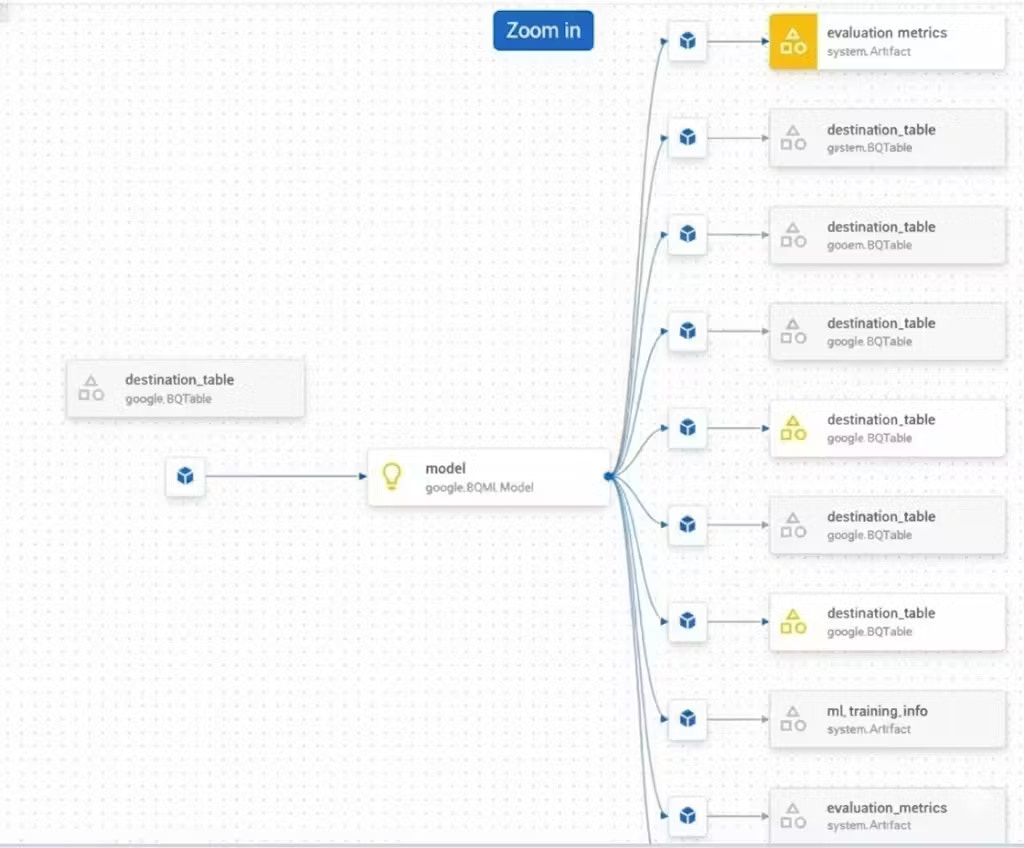
- JSON de l’artefact de modèle généré :
{ ... "instanceSchemaTitle": "google.BQMLModel", ... "schemaTitle": "google.BQMLModel", "schemaVersion": "0.0.1", } Prédictions générées par le pipeline :
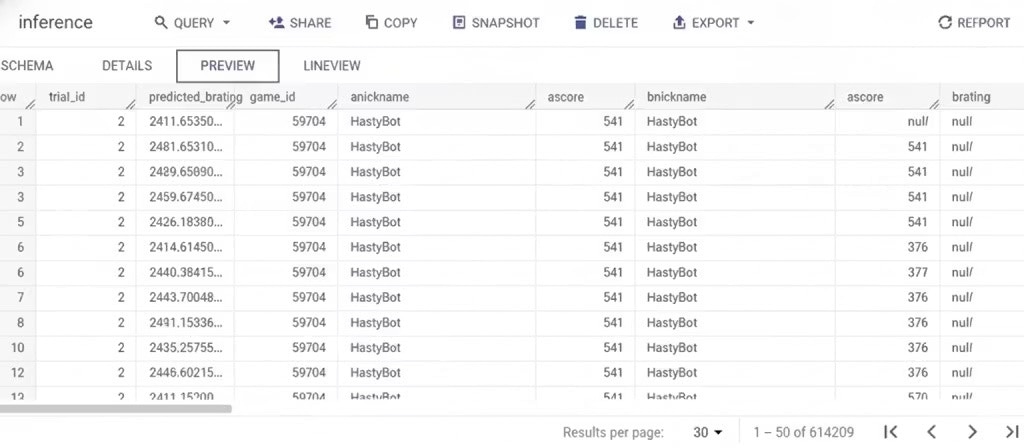
L’inférence est donnée dans la colonne « predicted_brating » de la table d’inférence.
Résumé :
Comme prochaine étape, tous les modèles BQML peuvent être entraînés dans le pipeline Vertex AI, et la sélection de modèle peut s’effectuer dans le pipeline lui-même, s’assurant ainsi que tous les types de variations dans les données sont capturés dans le meilleur modèle, fournissant ainsi les meilleurs résultats de régression possibles. Voici le pipeline Vertex AI pour le modèle BQML qui pourrait être démontré. D’autres pipelines possibles pourraient être réalisés avec le modèle AutoML, TensorFlow, PyTorch, Caffe et d’autres modèles de frameworks. De plus, les prédictions peuvent être visualisées écrites dans une table BigQuery et les artefacts étaient présents dans Vertex AI.
Références :
- https://google-cloud-pipeline-components.readthedocs.io/en/google-cloud-pipeline-components-1.0.40/
- https://cloud.google.com/vertex-ai/docs/pipelines/introduction
- https://cloud.google.com/bigquery-ml/docs/create-machine-learning-model
- https://cloud.google.com/bigquery/docs/reference/libraries-overview
