

AWS Glue est un service sans serveur qui effectue principalement des tâches d'extraction, de transformation et de chargement (ETL) en tirant parti d'Apache Spark, soit via l'API Python PySpark, soit avec le langage Scala. Il facilite le déplacement et le catalogage des mégadonnées en fonction du type de solutions utilisées, qu'il s'agisse de crawlers Glue ou de solutions basées sur le code, pour ajouter de nouvelles partitions de données, des tables et des bases de données. Les données provenant de sources telles qu'Amazon RDS et Amazon S3 peuvent être utilisées pour les tâches Glue ou d'autres, avec des cibles telles qu'Amazon Redshift. Glue permet aux spécialistes de la donnée de construire des workflows de bout en bout pour orchestrer des pipelines axés sur la donnée, de les provisionner à l’aide d’outils Infrastructure as Code (IaC), ainsi que de les intégrer et de les déployer facilement à l’aide d’AWS Code Build et AWS Code Pipeline.
Solution existante
Le diagramme suivant présente l’architecture globale de la solution et les étapes.
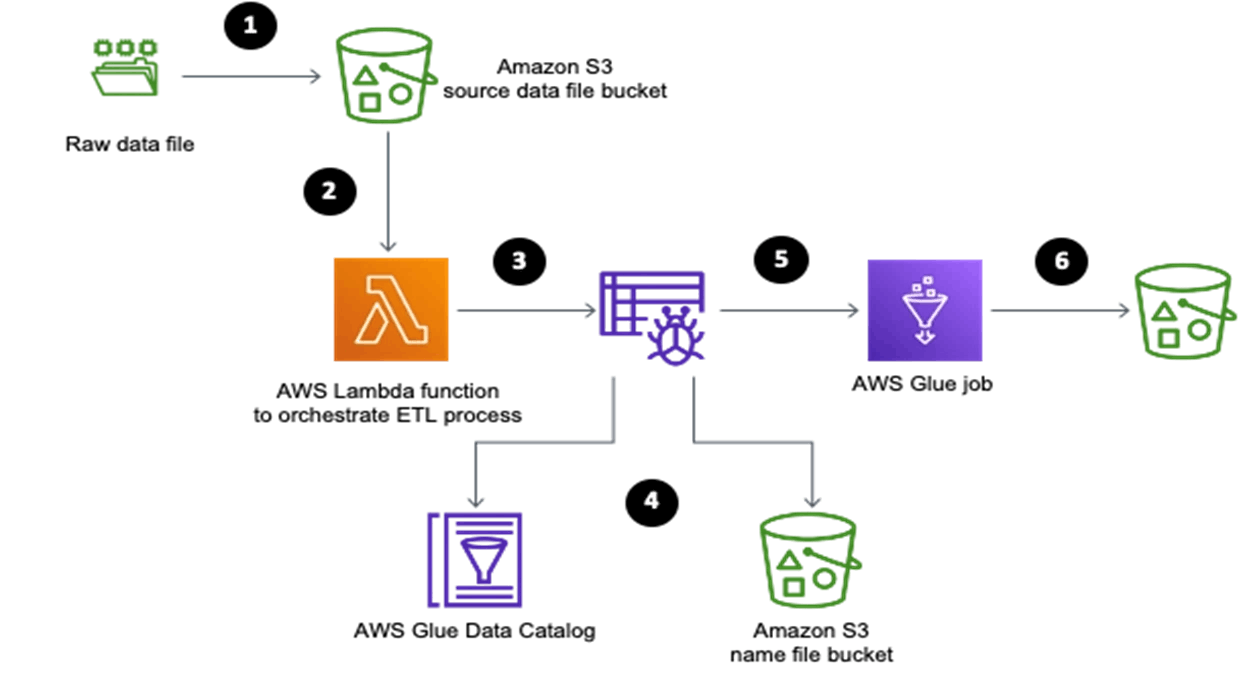
Limites d’AWS Glue
- Extension limitée des langages – AWS Glue ne prend en charge que quelques langages de programmation, dont Python et Scala
- Prise en charge limitée des frameworks – Impossible d’intégrer AWS Glue à un autre système ou application de service infonuagique
- Dans AWS Glue, les tâches utilisant la version 0.9 ou 1.0 d’AWS Glue ont une facturation minimale de 10 minutes, tandis que les tâches utilisant la version 2.0 ont une minute minimale
Défis de l’industrie
- AWS Glue permet uniquement de payer pour le temps d’exécution de la tâche ETL. AWS facture un tarif horaire basé sur le nombre d’unités de traitement des données (DPU) utilisées pour exécuter la tâche ETL.
- La taille importante des ensembles de données traités quotidiennement avec des instantanés complets de données entraîne une plus grande utilisation des ressources de traitement ETL, ce qui augmente le facteur de coût.
- Dans AWS, l’utilisateur ne peut pas contrôler les coûts tant que la taille des données ou les ressources de traitement ne sont pas réduites, ce qui n’est pas possible, même avec une logique de transformation.
- La plupart des données collectées sont brutes, provenant de sources de données hétérogènes ou homogènes et de petits fichiers, ce qui pose des problèmes lors de la transformation des données dans les couches suivantes.
Nouvelle solution proposée :
Snowflake est un entrepôt de données infonuagique qui offre une variété de fonctionnalités pour le stockage, la transformation et l’analyse des données. Un des avantages de l’utilisation de Snowflake est qu’il peut facilement être intégré à d’autres services AWS, tels qu’Amazon S3. Cette intégration rend possible la migration de données de S3 vers Snowflake en utilisant :
- La commande COPY pour la migration des données historiques
- Un Snow pipe pour l’ingestion de données en temps réel
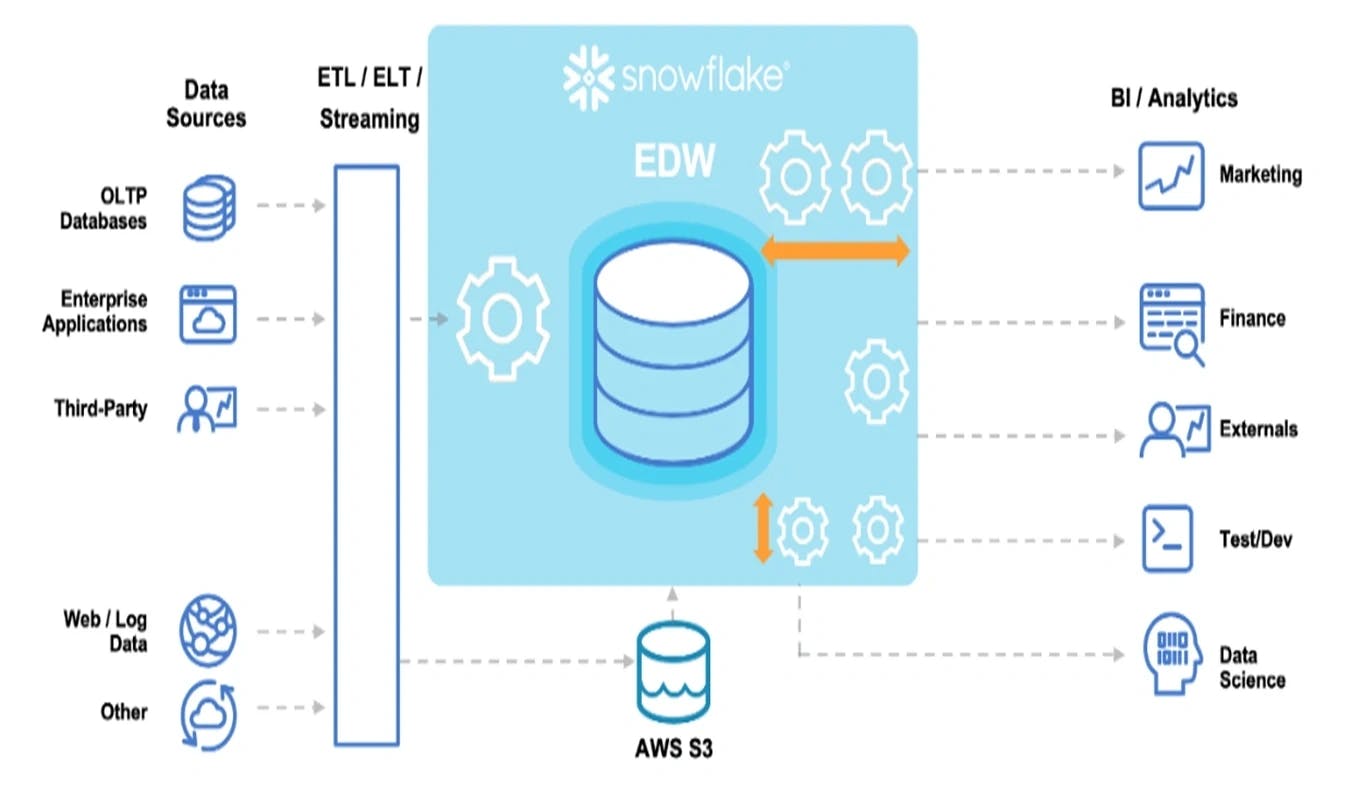
Architecture Snowflake
Création de valeur pour un client du point de vue du temps et des coûts
Nous avons complètement désactivé les fonctionnalités Glue, rarement utilisées dans le cas de la première configuration d’un ensemble de données ou pour des demandes spéciales. À l’avenir, nous pouvons continuer avec le traitement des données delta à l’aide du DWH Snowflake, qui offre un traitement et un calcul des données plus rapides.
En termes de coût, nous avons 400 à 500 Go de données par jour, qui doivent être traitées couche par couche et sont entièrement chargées pour la journée d’affaires D-1. Après la mise en place de la nouvelle solution, nous avons réduit les coûts de 3 000 $ par mois, ce qui a un impact important et profite au client en ce qui concerne les frais de calcul, les ressources et le temps, réduits de moitié par rapport aux exécutions précédentes.
Références :
https://aws.amazon.com/blogs/big-data/monitor-optimize-cost-glue-spark/
