

Vue d’ensemble
À l’ère numérique actuelle, le volume de données générées chaque jour est stupéfiant, atteignant environ 5 quintillions d’octets dans le monde. Les entreprises cherchent à exploiter cette richesse d’informations pour garder une longueur d’avance sur le marché. Cependant, un défi crucial se pose au milieu de cette profusion de données : garantir aux parties prenantes l’accès à des données de qualité afin de prendre des décisions éclairées.
Décrypter le paysage des données
Considérez une institution financière de premier plan en Amérique du Nord confrontée à de nombreux problèmes sur sa plateforme de données et d’analytique sur Google Cloud Platform (GCP). Ces points douloureux illustrent les défis plus larges auxquels font face les organisations naviguant dans le paysage complexe de la gestion des données :
- Données fragmentées : Les données sont dispersées à travers divers emplacements et services, ce qui gêne la consultation croisée fluide et la prise de décision
- Dilemme de la découverte des ensembles de données : L’absence de schéma cohérent ou de catalogue de données complique la recherche des ensembles pertinents et complique l’utilisation des données
- Casse-tête de la gouvernance : L’application des normes de gouvernance parmi des ensembles variés de données exige des protocoles d’accès et de surveillance robustes
- Labyrinthe de traçabilité des données : L’absence de mécanismes exhaustifs de traçabilité freine l’analyse des causes fondamentales
Bien qu’une solution sur mesure dans l’environnement Google Cloud puisse sembler attrayante, une approche plus pragmatique est nécessaire face à la complexité croissante. Il est crucial d’explorer des méthodes rationalisées pour surmonter ces défis, permettant une meilleure accessibilité, gouvernance et traçabilité des données sans compter sur des solutions personnalisées.
Notre voie à suivre
L’objectif principal de l’institution financière est l’unification des données provenant de différentes sources et la création d’un tableau de bord unique qui rassemble ses données avec sécurité et gouvernance. Nous étions certains que Goggle Dataplex était le bon choix pour relever ces défis. Google Dataplex est une solution intelligente de tissu de données permettant aux organisations de découvrir, gérer, surveiller et gouverner centralement des données provenant de multiples sources.
Voici les principaux composants de Dataplex.
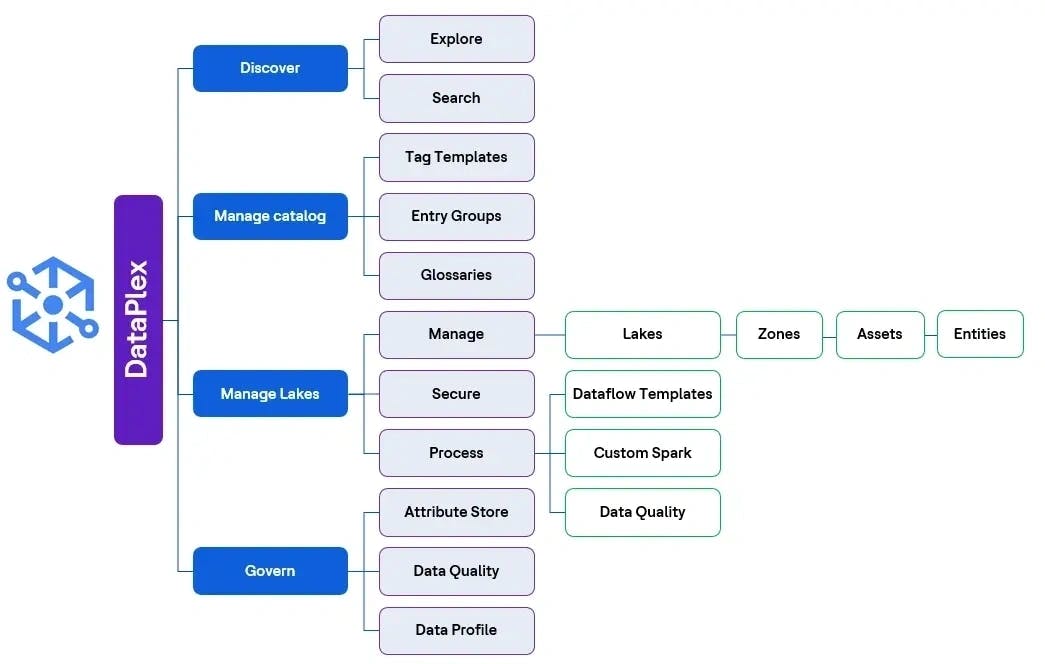
Approche de mise en œuvre
Configuration et mise en place de Dataplex :
| Étapes impliquées | Description | Approche de conception |
|---|---|---|
| Étape 1 : Mise en place du Metastore Dataproc (V2) | Nous avons d’abord établi un metastore Dataproc (V2) afin de profiter du cluster Dataproc pour le traitement Dataplex.
Lors de la configuration, il est essentiel de sélectionner le protocole « gRPC », car Dataplex fonctionne uniquement sur ce protocole.
La taille du cluster est adaptée selon le volume et la charge de travail afin d’assurer une performance optimale. | Nous utilisons le niveau développeur pour le développement et le niveau entreprise pour la production.
Des metastores distincts sont créés pour chacun : un pour le développement et un autre pour la production, personnalisés selon leurs exigences respectives.
L’instance de développement est définie à la taille ‘xs’, tandis que l’instance de production est dimensionnée à un.
MySQL sert de moteur de base de données pour le metastore Dataproc.
Les principales API, dont Cloud Dataplex, BigQuery, Cloud Dataproc et Cloud Composer, sont activées pour garantir une intégration et un fonctionnement fluides. |
| Étape 2 : Établissement des lacs et zones Dataplex | Ensuite, nous avons créé les lacs et zones Dataplex, en organisant les données selon les différents domaines et services. Des environnements personnalisés avec des packages spécifiques, tels que Python, peuvent être utilisés selon les besoins du projet lors de la création Dataplex. | Comme pour la configuration du metastore, nous utilisons le niveau développeur pour les environnements de développement, et le niveau entreprise pour les environnements de production.
Deux instances distinctes de lacs et zones Dataplex sont créées pour les environnements de développement et de production, chacune adaptée à leurs besoins respectifs.
MySQL est utilisé pour le metastore Dataproc, assurant la cohérence à travers l’environnement Dataplex.
Les API essentielles, notamment Cloud Dataplex API, BigQuery API, Cloud Dataproc et Cloud Composer API, sont activées pour appuyer l’intégration et le fonctionnement continu dans l’écosystème de données. |
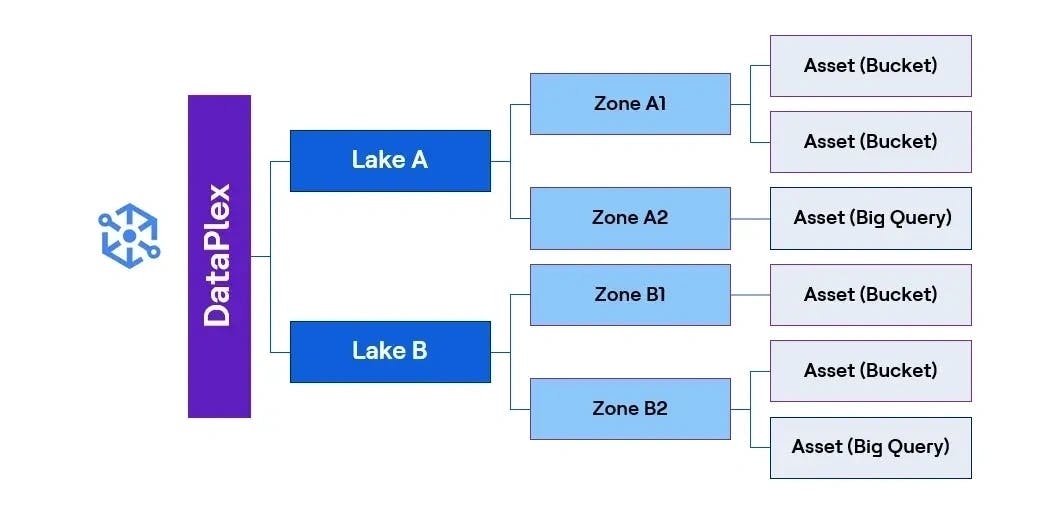
Cartographie des ressources et activation de la découverte des données
En intégrant les ressources sous leurs zones respectives, qu’il s’agisse de GCS (Google Cloud Storage) ou d’ensembles de données BigQuery, Dataplex génère automatiquement des métadonnées et permet la découverte des données. Cela permet l’intégration fluide des buckets GCS et des ensembles de données BigQuery via SQL dans le Workbench d’Exploration Dataplex. Ainsi, nous avons obtenu une organisation structurée des données pour divers services, une exploration transparente des données à travers lacs et zones et un temps de mise en marché réduit pour accroître l’efficacité opérationnelle. Voici la structure représentant les couches créées.
Contrôle d’accès granulaire
Nous avons établi les principes et attribué l’accès aux ressources en fonction des rôles, profitant de la flexibilité de Dataplex pour configurer l’accès tant au niveau des ressources qu’au niveau des principes. À l’aide d’IAM (Identity and Access Management), nous avons géré les principes et mis en place un contrôle d’accès fin tant au niveau DES DONNÉES qu’au niveau du LAC. Cette approche a permis un contrôle d’accès granulaire et une intégration fluide et des politiques IAM, facilitant le contrôle des accès basé sur les rôles et répondant à l’exigence de l’institution financière de restreindre l’exploration des données entre les zones.
Traitement des données
Nous avons exploité les modèles intégrés de Dataplex pour diverses tâches d’ingénierie des données, telles que la préparation, l’ingestion, les vérifications de qualité et les pipelines de dataflow. De plus, Dataplex prend en charge l’exécution de tâches Dataproc serverless personnalisées, orchestrées de façon centrale via Composer. En intégrant ces tâches dans nos processus de bout en bout, nous avons atteint des performances accrues, une orchestration et un suivi fluides par Composer. Nous avons également intégré harmonieusement les processus de qualité des données (DQ) aux pipelines existants de Composer, améliorant ainsi l’efficacité globale de nos flux de travail de données.
Qualité des données
Dataplex offre l’Auto data quality (AutoDQ) et des tâches de contrôle qualité pour valider les données :
- Auto data quality (AutoDQ) : AutoDQ automatise et simplifie la définition de la qualité grâce à des recommandations et des flux de travail guidés par interface. Nous pouvons créer des règles pour différentes dimensions et configurer leur exécution pour les données incrémentielles et complètes avec un seuil défini.
- Tâche de qualité des données Dataplex : La tâche de qualité utilise un composant open source, CloudDQ, qui peut aussi ouvrir des possibilités pour les clients voulant adapter le code à leurs besoins. Les règles peuvent être configurées dans un fichier YAML et référencées à partir d’un bucket GCS.
Notre approche de conception comportait plusieurs éléments clés :
- Tâches DQ personnalisées intégrées à Composer pour la flexibilité de l’orchestration
- AutoDQ utilisé pour certaines sources, optimisant l’efficacité
- Points de terminaison établis pour la consommation de données programmée, avec persistance des données dans le stockage BigQuery et récepteurs Cloud Logging, et prise en charge de l’intégration d’outils de rapports comme Looker et Google Data Studio
- Orchestration Dataplex pour la gestion de l’exécution et des opérations rationalisées
Cette approche a procuré d’importants bénéfices :
- Mise en œuvre simplifiée des dimensions de qualité, adaptables à divers besoins
- Amélioration des seuils de 40 % à 80 %, rehaussant la précision et la fiabilité des données
- Amélioration des performances et stabilité accrue des données, facilitant la prise de décision rapide et l’efficacité opérationnelle

Profilage des données
Nous avons analysé minutieusement les profils de données sources en configurant et en planifiant des vérifications à l’aide du module de profilage des données de Dataplex. Ce module identifie les caractéristiques statistiques clés telles que null %, unique % et distribution, offrant des métriques adaptées au type de colonne (par ex. : entier ou chaîne).
Notre approche de conception a consisté :
- À créer une analyse de profilage rattachée à une table BigQuery, avec la taille de l’échantillon déterminée selon la criticité des données sources
- À utiliser Looker Studio pour générer des aperçus issus du profilage sur une période donnée, améliorant la compréhension des données et les prises de décision
En plus du profilage, nous avons utilisé d’autres modules Dataplex pour faciliter la gestion efficace du catalogue et l’établissement de politiques de gouvernance, garantissant des pratiques exhaustives de gestion des données.
Gestion du catalogue
- Modèles d’étiquettes : Utiliser des étiquettes pour les données enrichit le contexte pour les parties prenantes. Par exemple, les étiquettes aident à identifier les tables contenant des données PII (information personnelle identifiante), les scores de qualité, la politique de conservation, etc.
- Groupes d’entrées : Une approche traditionnelle de la gestion de catalogue, où l’utilisateur peut créer des groupes pour leurs fichiers cloud et appliquer les politiques IAM précisant qui peut créer, modifier ou visualiser les entrées dans un groupe donné.
- Glossaire : Principalement utilisé dans les champs calculés, le glossaire est un endroit unique pour gérer la terminologie d’affaires et les définitions dans l’organisme.
- Magasin d’attributs : Sert à créer la taxonomie des attributs de données à rattacher aux ensembles de données.
Conclusion
Grâce à son tissu de données intelligent, Dataplex permet aux entreprises d’utiliser leurs données efficacement et de propulser l’analytique et la science des données. Nous considérons Dataplex comme un outil pivot pour unifier les actifs de données, améliorer leur gestion et offrir l’accès à des données de qualité. Il ne fait aucun doute que Dataplex est prêt à révolutionner les lacs de données et la gestion informationnelle, ayant un impact significatif sur les solutions de données à l’échelle de l’entreprise.
Pour plus d’informations sur Dataplex et pour commencer, contactez l’équipe Digital Business de HCLTech.

