
")
RAG est le système où les données sont stockées dans des magasins de connaissances et l'information liée à la requête de l'utilisateur est récupérée de ceux-ci pour l'ajouter, avec la requête de l'utilisateur, comme contexte supplémentaire avant de l'envoyer au LLM afin de générer une sortie plus précise et adaptée au contexte, d'où le nom Génération augmentée par récupération.
Architecture de haut niveau
Le schéma ci-dessous illustre un flux de travail RAG typique à haut niveau.
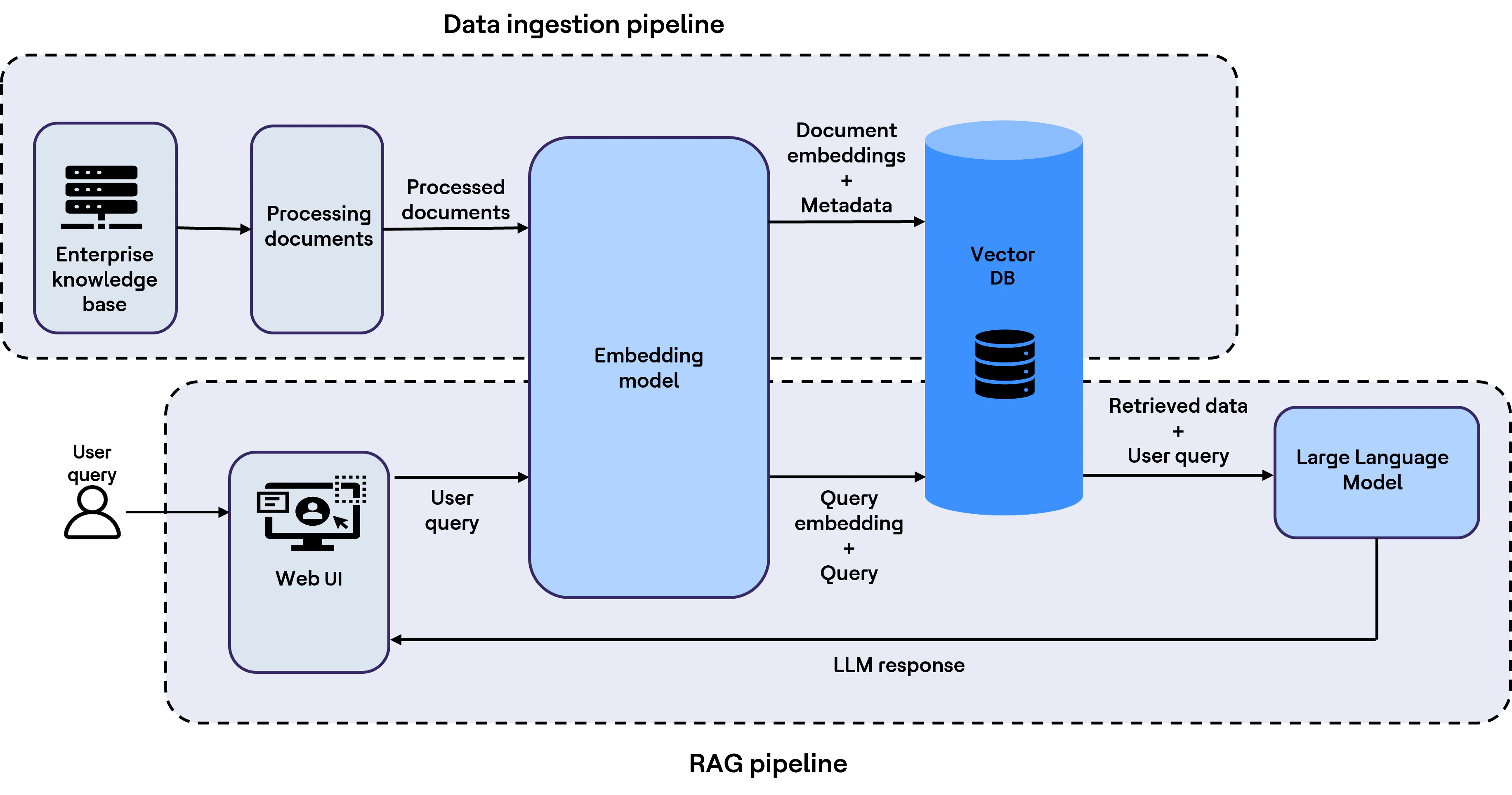
Les LLM sont entraînés sur de grands ensembles de données publics et sélectionnés, mais ils n’incluent généralement pas le contenu privé d’une entreprise, comme les politiques internes, les directives de codage, le code propriétaire et les documents d’affaires. RAG contribue à combler cet écart en ancrant les sorties du modèle dans la connaissance spécifique à l’entreprise au moment de la requête.
RAG vs l’ajustement fin : Quand vous utilisez vos propres données
Il existe deux façons courantes de rendre un LLM efficace sur les données d’entreprise :
- Peaufinez le modèle avec les données propres à votre entreprise.
- Utilisez le RAG pour extraire le contexte interne pertinent au moment de la requête.
En pratique, l’ajustement précis peut être coûteux, prendre beaucoup de temps et être complexe à gérer sur le plan opérationnel, surtout lorsque les connaissances de l’entreprise changent fréquemment. Pour cette raison, de nombreuses équipes commencent avec la RAG, car elle permet une itération plus rapide, un ancrage plus transparent et une maintenance plus facile.
Fonctionnement de la RAG (de bout en bout)
Pour rendre le flux de travail plus concret, cet article utilise une base de code comme source d’entrée à titre d’exemple. La même approche peut être appliquée à de nombreux types de contenu en entreprise, y compris les fichiers Word, PDF, tableurs, wikis et plus encore. Ce qui changera, ce sont la stratégie d’ingestion et de découpage.
Exemple utilisé : Fichiers de code source provenant d’un dépôt, bien que la même approche s’applique à d’autres types de contenu en entreprise.
Ci-dessous se trouve l’architecture du pipeline d’ingestion avec la base de code :
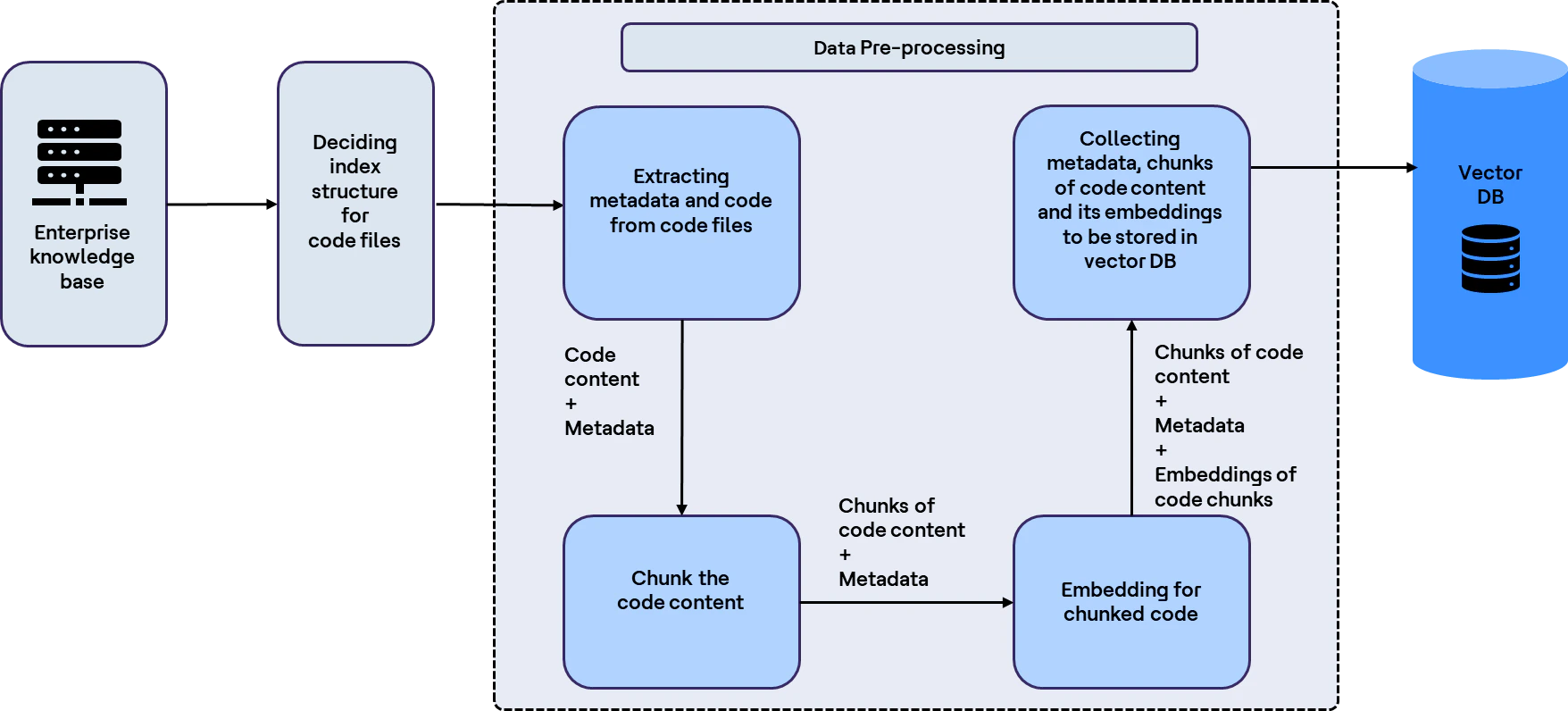
Étape 1 : Ingérer votre contenu
Un pipeline d’ingestion typique charge le contenu, le segmente, génère des embeddings et stocke les résultats dans un dépôt de connaissances, souvent une base de données vectorielle.
Étape 1.1 : Entrées
Dans cet exemple, l’entrée se compose des fichiers de code source dans votre dépôt.
Étape 1.2 : Traiter et stocker les données
Pour bâtir un pipeline RAG efficace, il est utile de comprendre quelques concepts clés.
Embeddings
Les embeddings sont des représentations numériques de données qui captent la signification sémantique. Ils permettent au système de comparer la similarité entre une requête utilisateur et le contenu stocké.
En convertissant le contenu source en embeddings, les systèmes RAG peuvent effectuer une recherche sémantique au lieu de se fier uniquement à l’appariement exact de mots-clés. C’est ce qui permet au système d’identifier de l’information pertinente même lorsque la formulation de la requête diffère de celle du contenu source.
Découpage
Le découpage est le processus qui consiste à diviser le contenu en segments plus petits et gérables avant de le stocker dans le pipeline RAG.
Cela est important pour deux raisons. Premièrement, les modèles d’embeddings ne peuvent traiter qu’une quantité limitée de données, ou de jetons, à la fois lors de la génération des embeddings. Deuxièmement, des segments plus petits et bien structurés améliorent la précision de la recherche en aidant le système à ne retourner que le contenu le plus pertinent pour une requête utilisateur.
Si des documents entiers sont stockés et récupérés sans découpage, trop de contexte non pertinent peut être envoyé au LLM. Cela peut diminuer la qualité des réponses, augmenter la latence et, dans certains cas, contribuer à des hallucinations ou à des résultats incomplets en raison des limites de la fenêtre de contexte.
De multiples outils sont disponibles pour soutenir le découpage, tels que les séparateurs de texte LangChain.
Remarque : Pour le code source, des analyseurs d’arbre de syntaxe abstraite (AST) peuvent être utilisés pour analyser et découper les fichiers de code de façon plus intentionnelle.
Méta-informations
Les méta-informations font référence aux autres données stockées avec le contenu et ses embeddings, afin d’améliorer la précision de la recherche et la facilité de gestion.
Voici des exemples de méta-informations :
- Nom du fichier
- Chemin du fichier
- ID du fichier
- Lien vers le dépôt
Les métadonnées sont utiles de plusieurs façons :
- Filtrage des résultats de recherche selon des informations liées au fichier comme le chemin du fichier, l’identifiant du fichier ou le lien du dépôt de fichiers.
- Prévention de la duplication des données lors de l’ingestion grâce à la possibilité de mettre à jour le contenu déjà présent dans le système RAG.
Indexation
L’indexation est le processus d’organisation des données afin de permettre une récupération plus rapide et plus efficace.
Dans le RAG, l’indexation devient particulièrement importante, car de grands volumes de contenu et les embeddings correspondants doivent être recherchés efficacement.
Trois grandes techniques d’indexation couramment utilisées dans le RAG sont :
- Index de fichiers inversés (IVF) : Les données sont converties en vecteurs et divisées en clusters.
- Quantification de produit (PQ) : Les données sont converties en vecteurs et quantifiées en codes compacts pour permettre une recherche efficace, souvent utilisée avec IVF sous la forme IVF-PQ pour les ensembles de données à grande échelle
- Petit monde navigable hiérarchique (HNSW) : Les données sont converties en vecteurs et stockées comme des nœuds dans un graphe à plusieurs couches. HNSW surpasse généralement IVF-PQ en termes de précision, bien qu'il consomme généralement plus d'espace de stockage.
Remarque : Les vecteurs créés par les techniques d’indexation sont différents des vecteurs d’embedding. Les vecteurs d’embedding stockent la signification sémantique, tandis que les vecteurs créés par les algorithmes d’indexation sont utilisés uniquement pour optimiser les opérations de recherche et ne représentent pas la signification sémantique.
Recherche de similarité
La recherche de similarité est la technique utilisée pour identifier le contenu dans le magasin de connaissances qui est le plus pertinent pour la requête de l’utilisateur.
Les deux approches de récupération les plus courantes sont :
- Recherche vectorielle
- Recherche par mots-clés
Lors de la mise en œuvre de la recherche de similarité dans RAG, deux algorithmes largement utilisés sont KNN et ANN.
- KNN (K plus proches voisins) : Trouve exactement les K plus proches voisins dans un ensemble de données. Bien que précis, il n'est pas toujours évolutif pour les grands ensembles de données, car la correspondance exacte peut être coûteuse en ressources de calcul
- ANN (Voisins approximativement les plus proches) : Trouve les voisins les plus proches de façon approximative beaucoup plus rapidement, sacrifiant un peu de précision au profit de la rapidité
Pour les systèmes RAG à grande échelle, la recherche ANN est couramment utilisée pour améliorer la vitesse de récupération sur de vastes ensembles de données. Dans de nombreuses mises en œuvre, l'ANN est d'abord utilisée pour identifier un ensemble de candidats des résultats les plus proches, comme les 100 ou 1000 voisins principaux, après quoi un raffinement plus précis avec le module KNN peut être appliqué pour améliorer la pertinence. Cette approche aide à équilibrer la rapidité, l'évolutivité et la précision de la récupération.
Pour mesurer la similarité entre la requête de l'utilisateur et les vecteurs stockés, des mesures de distance sont utilisées. Trois approches courantes sont :
- Distance euclidienne : Mesure la distance absolue entre les vecteurs
- Similarité cosinus : Mesure l’angle entre les vecteurs et est souvent efficace pour la comparaison sémantique
- Produit scalaire : Mesure l’alignement directionnel et la magnitude des vecteurs
Remarque : Comme les embeddings sont des vecteurs de haute dimension qui capturent des relations sémantiques, la similarité cosinus est souvent privilégiée pour la recherche de similarité. Elle est particulièrement efficace pour identifier la proximité conceptuelle entre la requête de l'utilisateur et le contenu récupéré, même si la formulation est différente.
Magasins de connaissances (BD de vecteurs)
Le RAG nécessite une couche de stockage, souvent appelée magasin de connaissances. Les bases de données de vecteurs sont couramment utilisées à cette fin.
Les BD de vecteurs sont des BD NoSQL spécialisées optimisées pour stocker et récupérer des données à partir de vecteurs de haute dimension, ou d'embeddings, à grande échelle. Elles sont conçues pour prendre en charge des milliards de vecteurs tout en permettant le filtrage par métadonnées.
Les BD SQL traditionnelles sont principalement conçues pour les requêtes à correspondance exacte. Lorsqu'on doit traiter des milliards de vecteurs de haute dimension, la correspondance exacte peut devenir trop lente, même avec l'indexation. C'est pourquoi les bases de données optimisées pour la recherche de vecteurs sont devenues essentielles pour les charges de travail RAG.
Exemples de bases de données de vecteurs :
- ChromaDB
- Pinecone
- Weaviate
Remarque : D'autres plateformes comme Redis et OpenSearch peuvent aussi prendre en charge la RAG puisqu'elles offrent des capacités de recherche par similarité. PostgreSQL prend maintenant en charge la recherche vectorielle grâce à l’extension pgvector.
Avec ces concepts établis, la prochaine étape consiste à déterminer comment les données d’entreprise doivent être traitées, structurées et stockées afin d’assurer une récupération efficace. La conception de la structure de l’index commence par une question pratique : Quel genre de requêtes les utilisateurs vont-ils poser ?
Dans le cas des dépôts de code, une requête typique pourrait être : « Trouve-moi le code où je peux ajouter une fonctionnalité de connexion. » Pour appuyer cela, le système RAG doit récupérer le contenu de code pertinent de manière efficace et précise.
C’est ici que les embeddings jouent un rôle essentiel. En générant et stockant des embeddings pour le contenu du code, le système peut exécuter une recherche sémantique vectorielle. Stocker le code original avec ces embeddings permet également une récupération basée sur les mots-clés, créant ainsi une expérience de recherche plus robuste dans l’ensemble.
Pour cet exemple, OpenSearch est utilisé comme base de données vectorielle afin de supporter à la fois le stockage et la récupération de contenu relié au code.
Exemple de la structure de l’index :

Voici deux propriétés de l’index :
- Dans les paramètres, le filtre k-NN est activé pour notre index afin d'effectuer une recherche ANN en utilisant le filtre k-NN. (Décrit en détail à l’étape 2)
- Les mappages contiennent la structure de l’index, c’est-à-dire l’information à enregistrer.
Les fichiers de code, les métadonnées (nom de fichier et chemin du fichier), le contenu du code du fichier et les intégrations du contenu du code sont stockés dans l’Index.
Dans la correspondance des intégrations, il y a deux attributs,
- le type est knn_vector, car les embeddings sont des vecteurs.
- la dimension, dépend du modèle d’embedding puisque différents modèles ont des dimensions différentes, comme pour le modèle text-embedding-ada-002 d’OpenAI, la dimension est 1536.
Étape 2 : Récupérer le contexte pertinent au moment de la requête
Au moment de la requête, le système parcourt le magasin de connaissances afin d’identifier les segments les plus pertinents à envoyer au LLM avec la question de l’utilisateur.
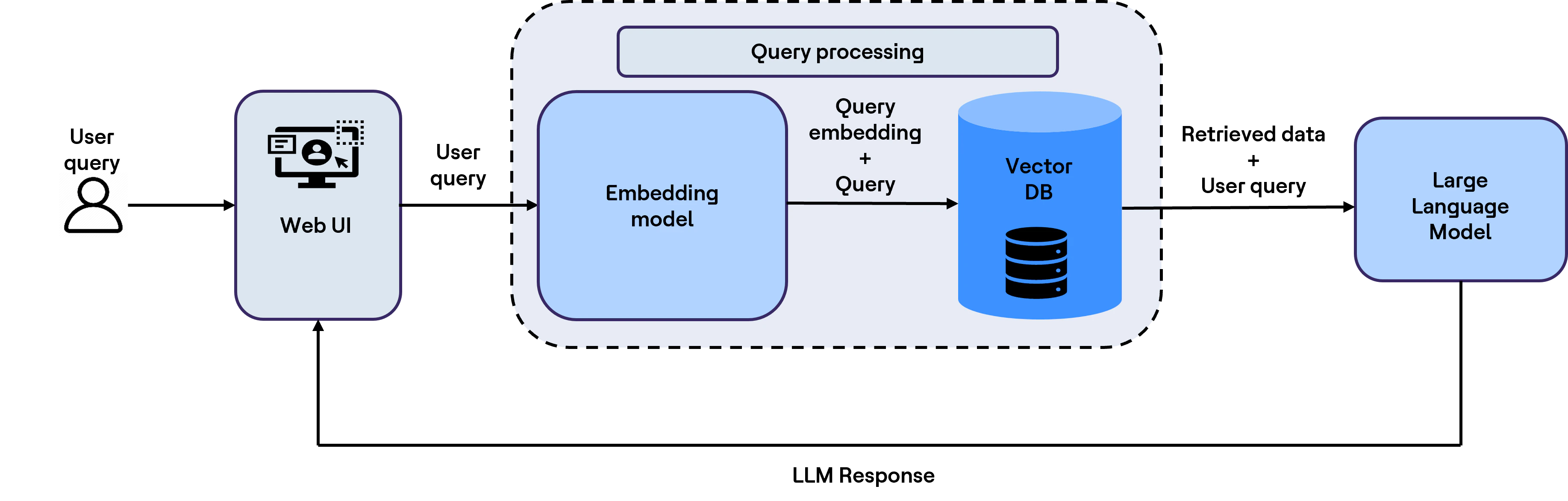
Pour effectuer une recherche dans la base de données vectorielle, la requête de l’utilisateur est d’abord convertie en une représentation d’incorporation, puisque la recherche vectorielle s’effectue sur des incorporations stockées. Ensuite, une requête de recherche est écrite, qui comprend un filtrage par métadonnées, une recherche par mots-clés et une recherche vectorielle pour effectuer une opération de recherche sur la base de données vectorielle (OpenSearch), comme dans l’exemple ci-dessous.

La sortie obtenue comprend les segments de code les plus pertinents ainsi que leurs métadonnées associées. Ceux-ci sont ensuite transmis au LLM avec la requête de l’utilisateur afin de générer des réponses plus précises, contextuelles et fondées sur les connaissances de l’entreprise.
Remarque : Des index plus avancés et complexes peuvent être créés selon le cas d’utilisation. Cela s’améliore généralement avec l’expérience alors prenez le temps d’expérimenter pour vos cas d’utilisation.
L’exemple ci-dessus utilise OpenSearch pour illustrer le fonctionnement interne du stockage et de la recherche dans un système RAG. Les bases de données vectorielles modernes telles que ChromaDB fournissent également un SDK qui simplifie la création des index, le stockage des données et les flux de travail de récupération.
Évaluation du système RAG
L’évaluation d’un système RAG consiste à mesurer à quel point il permet de récupérer du contenu pertinent et à quel point la réponse finale demeure fiable par rapport au contexte récupéré.
Les indicateurs d’évaluation typiques incluent :
- Rappel : Les documents ou extraits appropriés apparaissent-ils dans l’ensemble extrait ?
- Précision : Quelle proportion du contenu extrait est réellement pertinent ?
- Pertinence : Les extraits extraits correspondent-ils à l’intention de l’utilisateur ?
- Exactitude / taux d’hallucination : La réponse finale demeure-t-elle ancrée dans le contenu extrait ?
- Latence : Combien de temps l’extraction plus la génération prennent-elles par requête ?
L’évaluation et l’optimisation des systèmes RAG sont essentielles pour garantir une récupération d’information de haute qualité, pertinente et efficace. Comme l’illustre cet article, l’évaluation RAG n’est pas une étape finale. Il s’agit d’un exercice continu qui dépend du choix des bons modèles d’intégration, de la conception de stratégies de découpage efficaces, de l’application de filtres de métadonnées judicieux et de l’utilisation de techniques de recherche hybrides pour améliorer la précision.
L’utilisation de cadres établis tels que l’évaluation Langchain, l’évaluation LLamaIndex et le Système d’évaluation RAG (RAGAS) permet aux organisations d’évaluer de manière systématique à la fois la fiabilité et la rapidité de leurs mises en œuvre RAG.
Meilleures pratiques
Les meilleures pratiques, notamment la surveillance continue et l’amélioration itérative, garantissent que ces systèmes demeurent adaptables alors que les besoins de l’entreprise, les volumes de données et les attentes des utilisateurs évoluent. En ancrant les réponses du modèle dans le contenu récupéré et en optimisant la latence, les solutions RAG peuvent fournir des résultats plus précis, fiables et exploitables.
À mesure que l’écosystème RAG continue d’évoluer, un engagement soutenu envers l’évaluation et la qualité sera essentiel pour en libérer toute la valeur en entreprise et permettre une meilleure prise de décision, une plus grande productivité des développeurs et une innovation accrue à grande échelle.
Références :
