
")
RAG is the system where data is stored in knowledge stores and user-query related information is retrieved from the same for adding it along with the user query as additional context before sending it to LLM to generate more accurate and context-aware output, hence the name Retrieval-Augmented Generation.
High-level architecture
The diagram below illustrates a typical high-level RAG workflow.
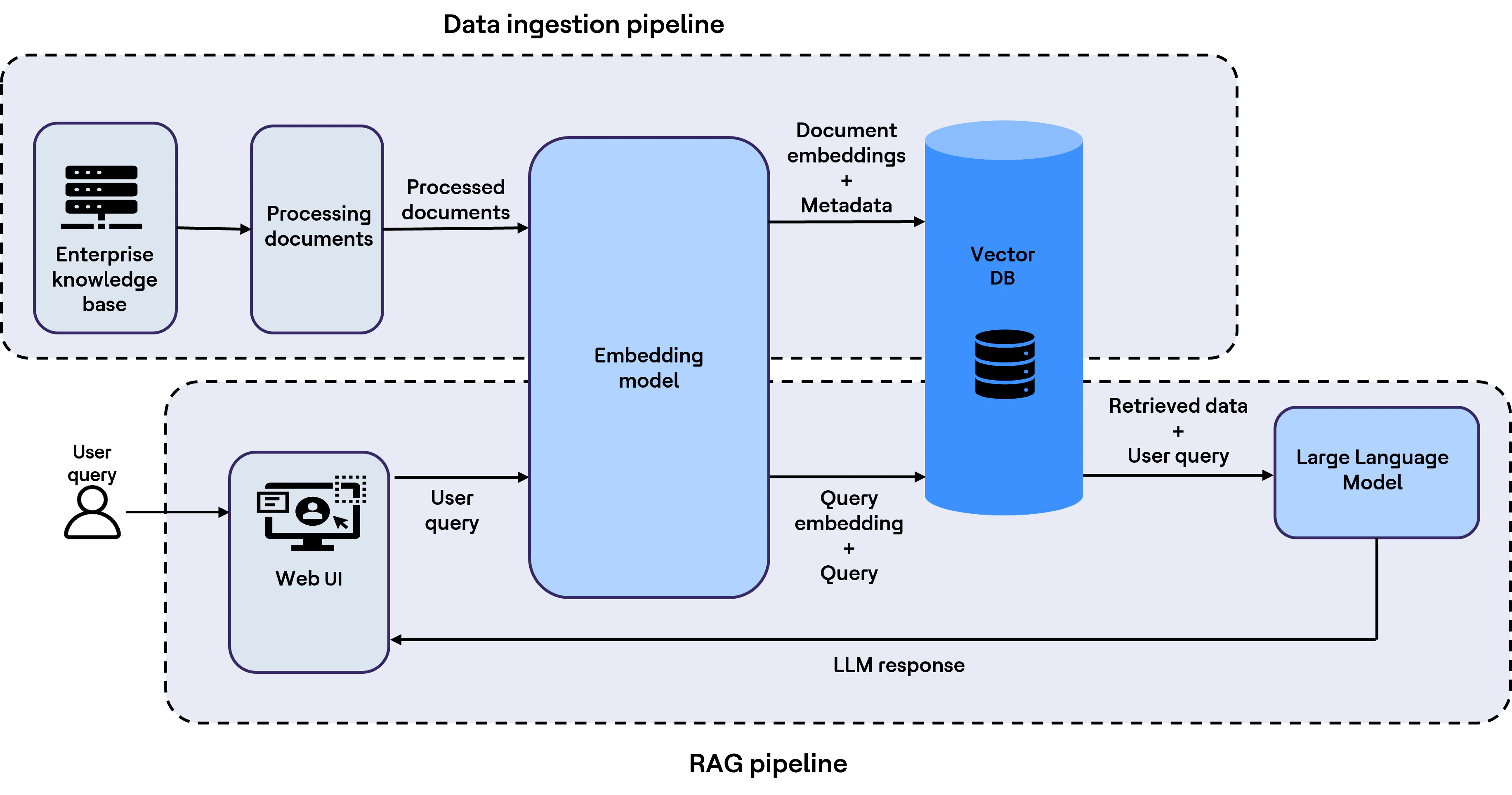
LLMs are trained on large public and curated datasets, but they generally do not include an enterprise’s private content, such as internal policies, coding guidelines, proprietary code and business documents. RAG helps bridge that divide by grounding model outputs in enterprise-specific knowledge at query time.
RAG vs. fine-tuning: When you bring your own data
There are two common ways to make an LLM effective on enterprise data:
- Fine-tune the model on your enterprise-specific data.
- Use RAG to retrieve the relevant internal context at query time.
In practice, fine-tuning can be expensive, time-intensive and operationally complex, particularly when enterprise knowledge changes frequently. For that reason, many teams begin with RAG because it enables faster iteration, more transparent grounding and easier maintenance.
How RAG works (end-to-end)
To make the workflow more tangible, this article uses a codebase as the example input source. The same approach can be applied across many enterprise content types, including Word document files, PDFs, spreadsheets, wikis and more. What will change is the ingestion and chunking strategy.
Example used: Source code files from a repository, though the same approach applies to other enterprise content types.
Below is the architecture of the ingestion pipeline of the same with code base:
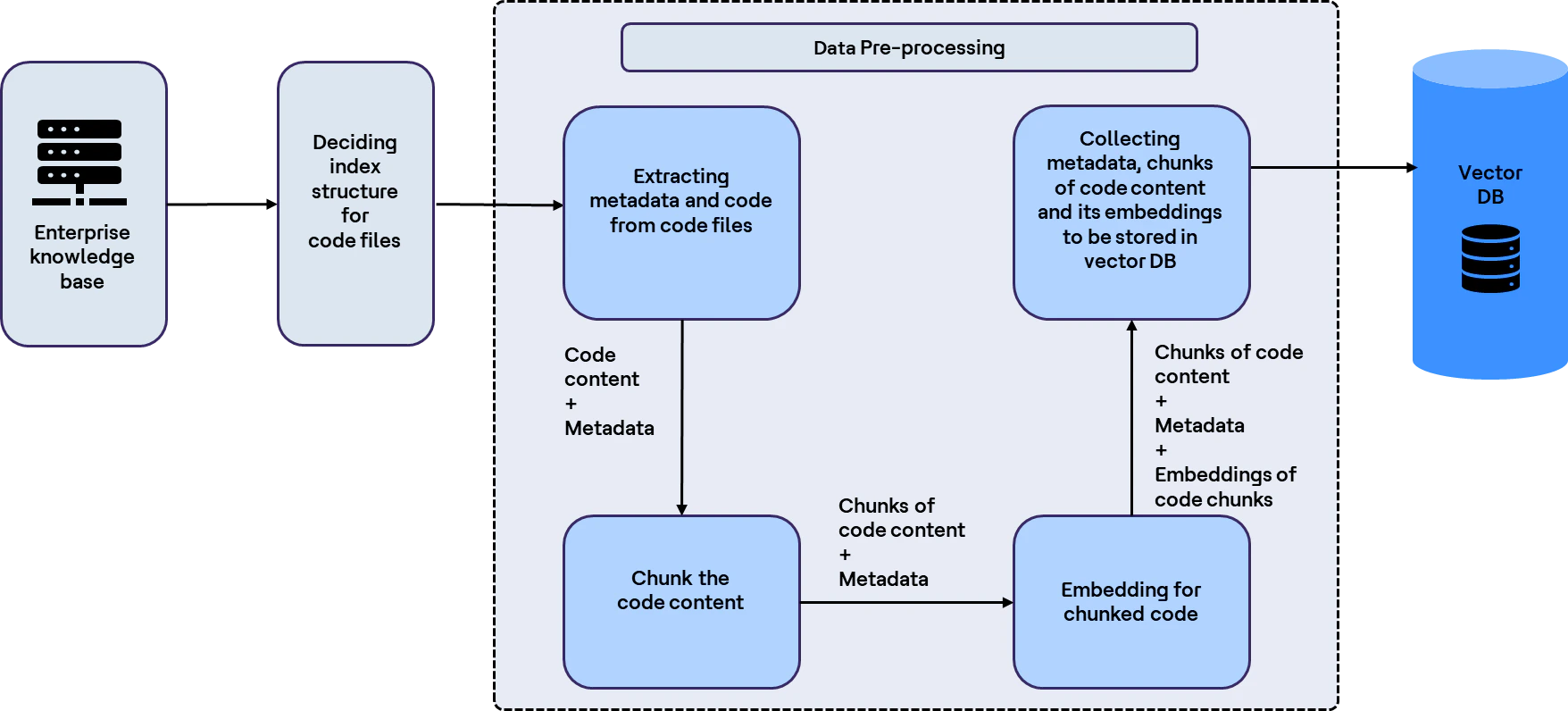
Step 1: Ingest your content
A typical ingestion pipeline loads content, chunks it, generates embeddings and stores the results in a knowledge store, often a vector database.
Step 1.1: Inputs
In this example, the input consists of the source code files in your repository.
Step 1.2: Process and store the data
To build an effective RAG pipeline, it is useful to understand a few core concepts.
Embeddings
Embeddings are numerical representations of data that capture semantic meaning. They enable the system to compare the similarity between a user query and the stored content.
By converting source content into embeddings, RAG systems can perform semantic retrieval rather than relying only on exact keyword matches. This is what allows the system to identify relevant information even when the wording in the query differs from the wording in the source content.
Chunking
Chunking is the process of splitting content into smaller, managable segments before storing it in the RAG pipeline.
This is important for two reasons. First, embedding models can process only a limited amount of data, or tokens, at a time when generating embeddings. Second, smaller, well-structured chunks improve retrieval precision by helping the system return only the most relevant content for a user query.
If entire documents are stored and retrieved without chunking, too much irrelevant context may be sent to the LLM. This can reduce response quality, increase latency and, in some cases, contribute to hallucinations or incomplete outputs due to context window limitations.
Multiple tools are available to support chunking, such as LangChain text splitters.
Note: For source code, Abstract Syntax Tree (AST) parsers can be used to parse and chunk code files more intentionally.
Metadata
Metadata refers to the other information stored alongside the content and its embeddings to improve retrieval accuracy and manageability.
Examples of metadata include:
- File name
- File path
- File ID
- Repository link
Metadata helps in several ways:
- Filtering search results based on file-related information like file path, file ID or file repository link.
- Preventing data duplication during data ingestion by enabling updates when content is already present in the RAG system.
Indexing
Indexing is the process of organizing data to enable faster and more efficient retrieval.
In RAG, indexing becomes especially important because large volumes of content and corresponding embeddings need to be searched efficiently.
Three major indexing techniques commonly used in RAG are:
- Inverted File Index (IVF): Data is converted into vectors and divided into clusters.
- Product Quantization (PQ): Data is converted into vectors and quantized into compact codes to enable efficient search, often used together with IVF as IVF-PQ for large-scale datasets
- Hierarchical Navigable Small World (HNSW): Data is converted into vectors and stored as nodes in a multi-layer graph. HNSW typically outperforms IVF-PQ in accuracy, though it generally consumes more storage space.
Note: The vectors created by indexing techniques are different from embedding vectors. Embedding vectors store semantic meaning, while vectors created by indexing algorithms are used for optimizing search operations only and do not represent semantic meaning.
Similarity search
Similarity search is the technique used to identify content in the knowledge store that is most relevant to the user’s query.
The two most common retrieval approaches are:
- Vector search
- Keyword search
When implementing similarity search in RAG, two widely used algorithms are KNN and ANN.
- KNN (K-Nearest Neighbors): Finds the exact K nearest neighbors in a dataset. While accurate, it is not always scalable for large datasets because exact matching can be computationally expensive
- ANN (Approximate Nearest Neighbors): Finds approximate nearest neighbors much faster, trading some accuracy for speed
For large-scale RAG systems, ANN search is commonly used to improve retrieval speed across vast datasets. In many implementations, ANN is first used to identify a candidate set of the nearest results, such as the top 100 or 1000 neighbors, after which a more precise KNN-plugin refinement can be applied to improve relevance. This approach helps balance speed, scalability and retrieval accuracy.
To measure similarity between the user query and stored vectors, distance metrics are used. Three common approaches are:
- Euclidean distance: Measures absolute distance between vectors
- Cosine similarity: Measures the angle between vectors and is often effective for semantic comparison
- Dot product: Measures the directional alignment and magnitude of vectors
Note: Since embeddings are high-dimensional vectors, that capture semantic relationships, cosine similarity is often preferred for similarity search. It is particularly effective in identifying conceptual closeness between the user query and retrieved content, even when the wording is different.
Knowledge stores (vector DBs)
RAG requires a storage layer, often referred to as a knowledge store. Vector databases are commonly used for this purpose.
Vector DBs are specialized NoSQL DBs optimized for storing and retrieving data from high-dimensional vectors, or embeddings), at scale. They are designed to support billions of vectors while also enabling metadata filtering.
Traditional SQL DBs are built primarily for exact-match queries. When dealing with billions of high-dimensional vectors, exact matching can become too slow, even with indexing. This is why databases optimized for vector search have become essential for RAG workloads.
Examples of vector databases include:
- ChromaDB
- Pinecone
- Weaviate
Note: Other platforms such as Redis and OpenSearch can also support RAG because they provide similarity search capabilities. PostgreSQL now supports vector search as well through the pgvector extension.
With these concepts established, the next step is to determine how enterprise data should be processed, structured and stored for effective retrieval. Designing the index structure begins with a practical question: What kind of queries will users ask?
In the case of code repositories, a typical query might be: “Find me the code where I can add login functionality.” To support this, the RAG system must retrieve relevant code content efficiently and accurately.
This is where embeddings play a critical role. By generating and storing embeddings for code content, the system can perform semantic vector search. Storing the original code alongside those embeddings also enables keyword-based retrieval, creating a more robust search experience overall.
For this example, OpenSearch is used as the vector database to support both storage and retrieval of code-related content.
Example of the index structure:

Here are two properties of the index:
- In Settings, the k-NN filter is set to ON for our index to perform ANN search using the k-NN filter. (Discussed in detail in Step 2)
- Mappings contain the index structure, i.e., the information to be stored.
Code files, metadata (file name and file path), file code content and code content embeddings are stored in the Index.
Within the embedding mapping, there are two attributes,
- type is knn_vector, as embeddings are vectors.
- dimension, depends on the embedding model as different models have different dimensions, like for OpenAI’s text-embedding-ada-002 model dimension is 1536.
Step 2: Retrieve relevant context at query time
At query time, the system searches the knowledge store to identify the most relevant chunks to send to the LLM along with the user’s question.
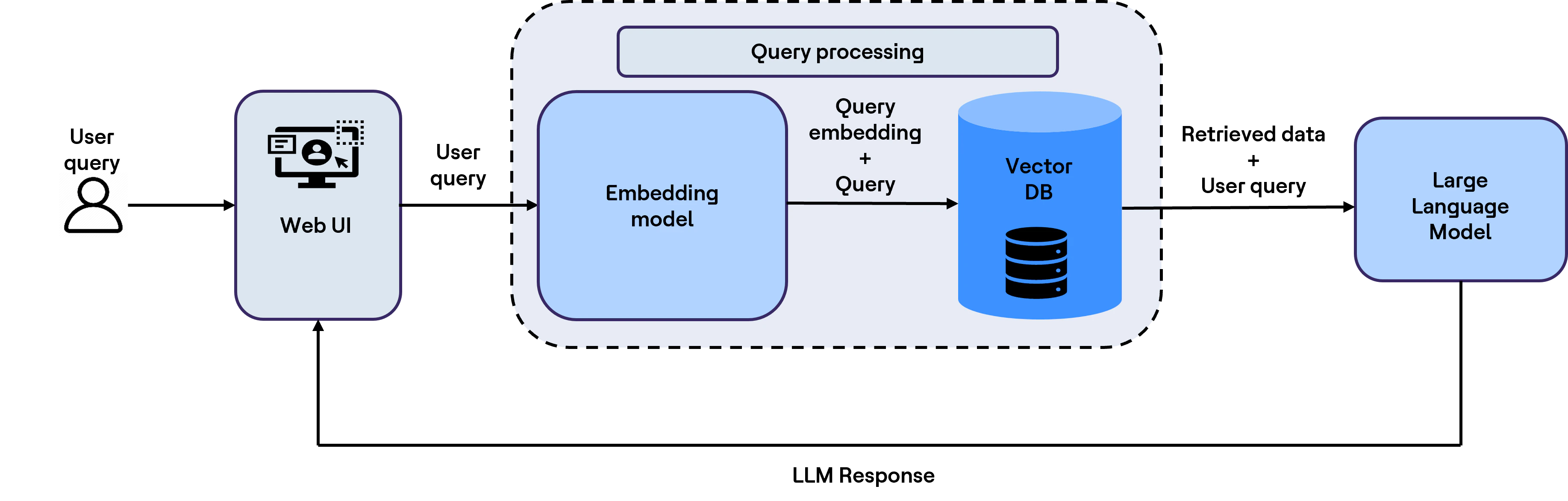
To search the vector DB, the user query is first converted into an embedding, since vector search is performed over stored embeddings. Next, a search query is written, which includes metadata filtering, keyword search and vector search to perform a search operation on the vector DB (OpenSearch), as per the example below.

The retrieved output includes the most relevant code chunks along with their associated metadata. These are then passed to the LLM together with the user query to generate responses that are more accurate, context-aware and grounded in enterprise knowledge.
Note: More advanced and complex indices can be built depending on the use case. This typically improves with experience, so take time and experiment for use cases.
The example above uses OpenSearch to illustrate the internal mechanics of storing and searching within a RAG system. Modern vector DBs such as ChromaDB also provide an SDK that simplify index creation, data storage and retrieval workflows.
Evaluating the RAG system
Evaluating a RAG system means measuring how effectively it retrieves relevant content and how reliably the final response remains grounded in that retrieved context.
Typical evaluation metrics include:
- Recall: Are the correct documents or chunks appearing in the retrieved set?
- Precision: How much of the retrieved content is actually relevant?
- Relevance: Are the retrieved chunks aligned with the user’s intent?
- Accuracy / hallucination rate: Does the final answer remain grounded in the retrieved content?
- Latency: How long does retrieval plus generation take per query?
Evaluating and refining RAG systems is critical to achieving high-quality, relevant and efficient information retrieval As this article illustrates, RAG evaluation is not a final checkpoint. It is an ongoing discipline that depends on selecting the right embedding models, designing effective chunking strategies, applying thoughtful metadata filtering and using hybrid search techniques to enhance accuracy.
Leveraging established frameworks such as Langchain evaluation, LLamaIndex evaluation and RAG Assessment System (RAGAS) enables organizations to systematically assess both the reliability and speed of their RAG implementations.
Best practices
Best practices, including ongoing monitoring and iterative improvement, ensure that these systems remain adaptable as business needs, data volumes and user expectations evolve. By grounding model responses in retrieved content and optimizing latency, RAG solutions can deliver outputs that are more precise, trustworthy and actionable.
As the RAG landscape continues to evolve, sustained focus on evaluation and quality will be essential to unlocking its full enterprise value and enabling better decision-making, stronger developer productivity and more effective innovation at scale.
References:
