

Dans le domaine en évolution rapide de l’IA, les modèles de langage sont devenus une pierre angulaire de nombreuses applications modernes, qu’il s’agisse de chatbots ou d’outils de génération de contenu. Bien que les grands modèles de langage (LLM), comme la série GPT d’OpenAI, aient attiré une attention considérable pour leurs capacités impressionnantes, ils présentent des défis. Des coûts informatiques importants, des demandes de ressources élevées et des enjeux de confidentialité des données figurent parmi les facteurs qui ont entraîné un virage vers des solutions plus spécialisées.
C’est ici qu’entrent en jeu les petits modèles de langage (SLM). Conçus pour répondre aux besoins spécifiques des entreprises et des secteurs qui exigent des capacités de traitement du langage sur mesure, les SLM offrent une alternative plus ciblée et efficace. Contrairement aux LLM, les SLM sont optimisés pour l’efficacité, les rendant accessibles à un éventail plus large d’utilisateurs sans compromettre les performances pour des applications de niche. Alors que les entreprises recherchent des solutions d’IA plus intelligentes et durables, comprendre le rôle des SLM est essentiel pour naviguer dans l’avenir du traitement du langage.
Dans ce blogue, nous explorerons ce que sont les SLM, leur pertinence dans le monde des affaires actuel, la manière dont ils se comparent aux LLM et ce que l’avenir réserve à cette technologie émergente.
Comprendre les bases : SLM vs LLM
Un SLM est un modèle d’IA générative compact avec moins de paramètres et une architecture de réseau neuronal plus petite qu’un LLM. Les SLM sont entraînés sur un ensemble de données plus petit, plus spécifique et souvent de meilleure qualité que les LLM.
Imaginez les modèles de langage comme des pièces d’un vaste casse-tête. Les LLM sont comme d’énormes pièces détaillées qui forment les parties complexes et étendues du casse-tête. Ils gèrent la complexité et réunissent des éléments variés afin de créer une image large et exhaustive. Les SLM, par contre, sont des pièces plus petites et plus spécialisées — ces formes essentielles qui s’emboîtent parfaitement dans des zones ciblées, complétant le casse-tête de manière impossible pour les plus grosses pièces.
Tout comme les gros et les petits morceaux sont essentiels pour résoudre un casse-tête, les LLM et les SLM jouent chacun un rôle crucial dans le traitement du langage. Les LLM offrent l’amplitude et la profondeur nécessaires aux tâches complexes, tandis que les SLM fournissent la précision et le ciblage requis pour accomplir des tâches plus simples et spécifiques. En d’autres termes, les SLM comblent les lacunes, garantissant que tous les aspects du casse-tête s’assemblent parfaitement.

Analyse comparative
| Aspect | SLM | LLM |
|---|---|---|
| Paramètres | Des millions à quelques milliards | Des dizaines ou des centaines de milliards à des milliers de milliards |
| Performance | Meilleure performance pour des tâches plus simples ou spécifiques | Excellente compréhension et génération du langage complexe |
| Ensemble de données | Spécifique à un domaine | Entraîné sur une vaste source de données |
| Entraînement et ressources | Nécessitent moins de puissance de calcul, de mémoire et de stockage | Nécessitent une importante quantité de ressources informatiques, de mémoire et de stockage |
| Prix | Relativement moins cher | Coûteux |
| Cas d’utilisation | Systèmes embarqués, applications mobiles et dispositifs IdO | Chatbots avancés, création de contenu et systèmes de traduction complexes |
| Déploiement | Plus facile à déployer sur diverses plateformes | Nécessitent souvent du matériel spécialisé et de puissants serveurs infonuagiques |
| Adaptabilité | Peuvent être rapidement adaptés pour des tâches ou domaines spécifiques | Offrent une plus grande flexibilité mais nécessitent un effort important d’adaptation |
| Sécurité | Moins de risques d’exposition grâce à un moindre déploiement | Risque accru en raison d’une plus grande surface d’attaque et d’une dépendance à l’infrastructure infonuagique |
Cas d’utilisation des SLM
Alors que les LLM excellent pour traiter des tâches complexes et larges, les SLM offrent des avantages distincts dans des scénarios précis :
- Efficacité des ressources : Les SLM nécessitent beaucoup moins de puissance de calcul et de mémoire, ce qui réduit les coûts de déploiement et d’exploitation, particulièrement dans les environnements où les ressources sont limitées.
- Détail : Les SLM peuvent alimenter des kiosques en magasin qui fournissent aux clients des renseignements sur les produits et des recommandations personnalisées sans exiger une infrastructure dorsale étendue.
- Temps de réponse plus rapides : Leur taille plus petite permet aux SLM de traiter et de produire des réponses plus rapidement, ce qui est crucial pour les applications en temps réel.
- Service à la clientèle : Dans le secteur des télécommunications, les SLM peuvent être utilisés dans les centres d’appel pour traiter rapidement les demandes courantes des clients, réduisant ainsi les temps d’attente et améliorant la satisfaction.
- Efficacité énergétique : Les SLM consomment moins d’énergie, ce qui en fait un choix durable, particulièrement pour les entreprises qui souhaitent réduire leur empreinte carbone.
- Appareils domotiques intelligents : Les SLM peuvent être intégrés dans des assistants domestiques intelligents pour gérer efficacement des tâches telles que le contrôle de l’éclairage et des appareils, offrant ainsi des solutions écologiques.
- Souplesse de déploiement : Les SLM se déploient facilement sur des dispositifs périphériques, dans des systèmes IdO et dans des environnements à connectivité limitée.
- Santé : En milieux de soins éloignés ou ruraux, même là où l’accès à Internet est restreint, les SLM peuvent être déployés sur des appareils portables pour aider au diagnostic des patients et à la tenue de dossiers.
- Rentabilité : Pour de nombreuses tâches, l’écart de performance entre SLM et LLM peut être minime, faisant des SLM une solution plus économique sans compromettre la qualité.
- Éducation : Les établissements d’enseignement peuvent utiliser des SLM pour créer des outils d’apprentissage personnalisés abordables et des systèmes de correction automatisée, rendant les ressources éducatives avancées accessibles à un plus large public.
- Spécialisation : Les SLM peuvent être adaptés à des tâches ou des domaines précis, offrant des performances hautement spécialisées sans l’envergure d’un modèle plus volumineux.
- Finance : Les institutions financières peuvent adapter les SLM pour des tâches comme la détection de fraude ou l’évaluation des risques, offrant des solutions efficaces et adaptées à chaque besoin spécifique.
Bien que les LLM soient indéniablement puissants, les SLM présentent des avantages pratiques en matière d’efficacité, de rapidité et de rentabilité, faisant d’eux un choix judicieux pour de nombreuses applications concrètes.
Leaders du marché
Le tableau suivant présente les leaders du marché des SLM ainsi que leurs innovations et avancées.
| Entreprise mère | Modèle | Année de lancement | Paramètres | Longueur du contexte | Principales caractéristiques |
|---|---|---|---|---|---|
| Microsoft | Phi-1 | Juin ’23 | 1,3B | 2K | Performance de pointe aux évaluations de programmation Python. |
| Phi-1.5 | Sept. ’23 | 1,3B | 2K | Performance comparable à des modèles 5x plus gros, axée sur le raisonnement du bon sens et la compréhension du langage. | |
| Phi-2 | Déc. ’23 | 2,7B | 2K | Raisonnement exceptionnel et capacités avancées de compréhension du langage; égale ou surpasse des modèles jusqu’à 25x plus grands. | |
| Phi-3-mini | Juin ’24 | 3,8B | 4K et 128K | Premier de sa catégorie à supporter une fenêtre de contexte jusqu’à 128K jetons, optimisé pour divers matériels. | |
| Phi-3-small | Avril ’24 | 7B | 8K | Surpasse des modèles beaucoup plus gros, y compris GPT-3.5T. | |
| Phi-3-medium | Avril ’24 | 14B | 8K | Performance élevée sur les tests de langage, raisonnement, codage et mathématiques. | |
| Mistral IA | Mixtral 8x7B | Déc. ’23 | 56B | 32K | Modèle mélange d’experts utilisant des modèles spécialisés pour différentes tâches, avec mécanisme de validation pour choisir le meilleur à chaque entrée; excelle en tests de code et de raisonnement. |
| Meta | LLaMA 3.1 | Juillet ’24 | 8B, 70B, 405B | 128K | Excellent en connaissances générales, mathématiques, utilisation d’outils, génération de données synthétiques et traduction multilingue. |
| Gemma 7B | Avril ’24 | 7B | 8K | Déploiement efficace, excellente performance pour les réponses aux questions, le raisonnement, les mathématiques et la programmation. |
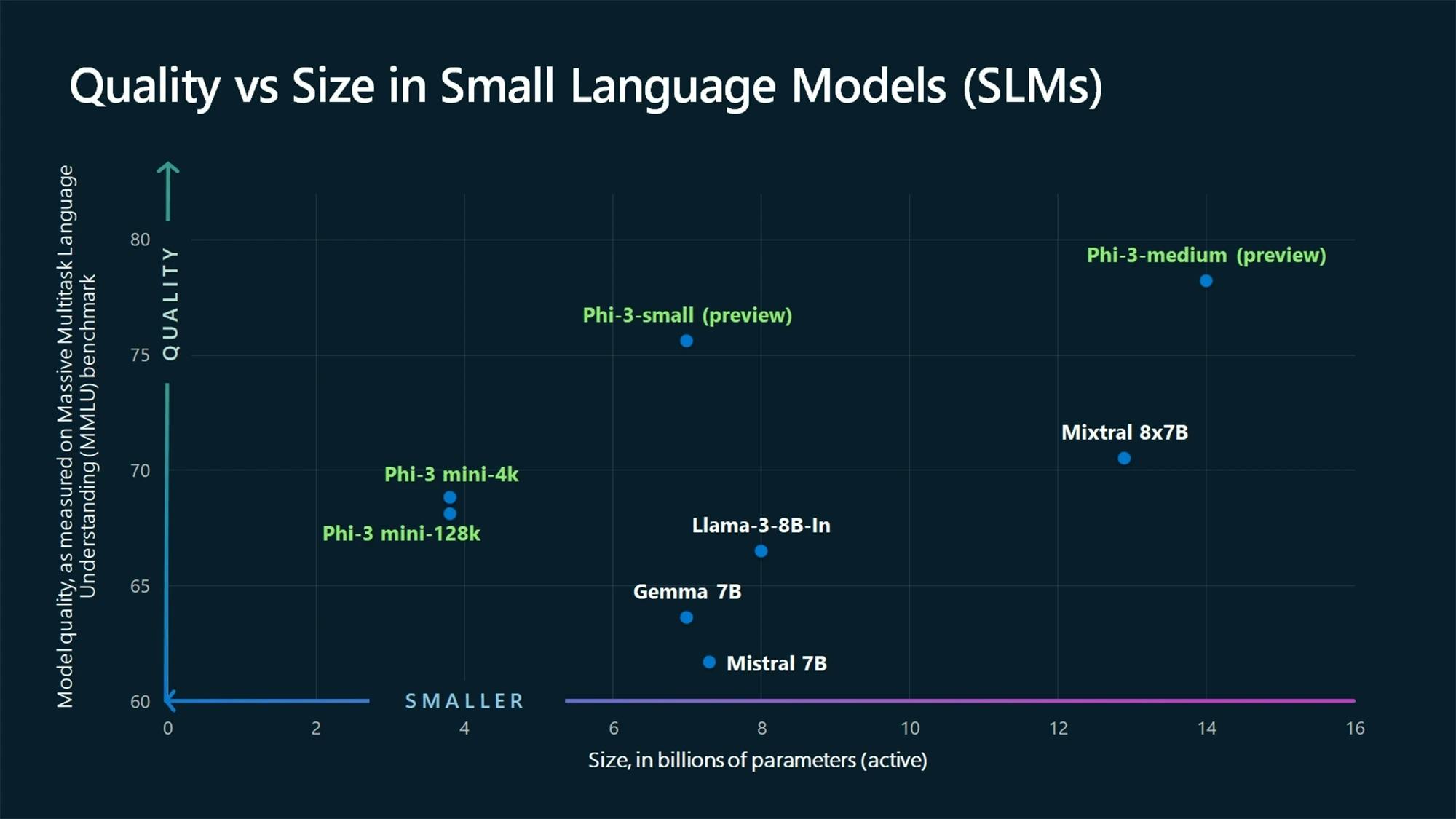
Le graphique suivant illustre la relation entre la taille du modèle et la qualité, mettant en évidence comment les avancées dans l’architecture des modèles et les données d’entraînement ont eu un effet sur leur performance.
Défis des SLM à relever
L’analyse du Hughes Hallucination Evaluation Model (HHEM) Leaderboard met en lumière comment les nouveaux SLM réduisent l’écart de performance avec les LLM, mais plusieurs défis subsistent.
| Type | Modèle | Taux d’hallucination | Taux de cohérence factuelle |
|---|---|---|---|
| SLM | Phi-2 | 8,5 % | 91,5 % |
| Phi-3-mini-4K | 5,1 % | 94,9 % | |
| PhiPhi-3-mini-128k | 4,1 % | 95,9 % | |
| Mixtral 8x7B | 9,3 % | 90,7 % | |
| LLaMA 3.1-405B | 4,5 % | 95,6 % | |
| Gemma 7B | 7,5 % | 92,5 % | |
| LLM | GPT-4 Turbo | 2,5 % | 97,5 % |
| GPT-3.5 Turbo | 3,5 % | 96,5 % | |
| LLaMA-2-70B | 5,1 % | 94,9 % | |
| Google Gemini 1.5 Pro | 4,6 % | 95,4 % |
Le classement HHEM évalue la fréquence des hallucinations dans des résumés de documents générés par des LLM à l’aide d’un ensemble de 1 006 documents issus de plusieurs ensembles de données publics, principalement le corpus CNN/Daily Mail.
- Taux d’hallucination : Des SLM plus récents comme Phi-3-mini-128k (4,1 %) et LLaMA 3.1-405B (4,5 %) affichent des taux d’hallucination moindres que les premiers modèles tels que Mixtral 8x7B (9,3 %). Ils demeurent toutefois derrière les LLM comme GPT-4 Turbo, qui affiche un taux de 2,5 %.
- Taux de cohérence factuelle : GPT-4 Turbo mène avec un taux de cohérence factuelle de 97,5 %, alors que Phi-3-mini-128k (95,9 %) et LLaMA 3.1-405B (95,6 %) offrent aussi un rendement élevé mais nécessitent encore des améliorations.
Les LLM comme GPT-4 Turbo, avec leur faible taux d’hallucinations et leur grande cohérence factuelle, établissent des standards élevés. Tandis que les nouveaux SLM tels que Phi-3-mini-128k et LLaMA 3.1-405B comblent l’écart, ils doivent surmonter des défis en matière de justesse et de fiabilité pour égaler les LLM de tête, tout en maintenant de faibles coûts et des temps de traitement rapides.
Perspectives d’avenir
Si l’on se penche sur l’avenir des SLM, leur succès dépendra en grande partie de leur capacité à conjuguer performance et efficacité. Avec la demande croissante d’applications propulsées par l’IA, les SLM doivent prouver qu’ils peuvent livrer de façon constante des résultats précis et pertinents sur le plan contextuel, tout en réduisant les coûts de calcul et la consommation d’énergie. Leur flexibilité d’adaptation à divers cas d’utilisation et leur intégration harmonieuse à des systèmes existants seront aussi essentielles.
Au final, l’avenir des SLM sera tributaire de leur faculté à offrir des solutions robustes et évolutives qui répondent à la diversité des besoins des utilisateurs et des industries. À mesure que l’IA évolue, le rôle des SLM deviendra sans doute plus important, surtout dans des milieux où l’efficacité, la spécialisation et la durabilité sont clés. Cela nous invite à réfléchir à l’avenir de l’IA et aux facteurs décisifs qui en façonneront la trajectoire, positionnant les SLM comme une composante vitale du paysage de l’IA.
Références



