

La puissance sans précédent de l’IA transforme l’industrie des sciences de la vie (LS) dans toute la chaîne de valeur pharmaceutique, de la recherche et développement et des essais cliniques à la pharmacovigilance. L’impact et la valeur constatés grâce à la mise en œuvre de l’IA incitent les entreprises du secteur LS à agir de manière proactive pour acquérir et adopter rapidement ces outils, de peur de rater des opportunités.
À mesure que l’IA évolue, les considérations éthiques, la confidentialité des données et les défis réglementaires doivent être traités avec soin afin d’assurer une mise en œuvre responsable et digne de confiance. Les applications de l’IA dans le secteur des sciences de la vie doivent respecter les préoccupations relatives à la confidentialité des données soulevées par les autorités réglementaires, l’industrie en général et les patients.
La fusion de l’IA avec les données LS soulève de nombreuses questions éthiques qui nécessitent une stratégie bien documentée et approuvée avant l’adoption.
- Les données en temps réel sont-elles disponibles ?
- Dans quelle mesure l’ensemble de données LS est-il compatible avec la solution souhaitée ou réelle ?
- La qualité des données est-elle suffisante ?
- Le volume des données est-il suffisant pour l’analyse ?
- Les données sont-elles sûres, sécurisées et conformes aux exigences réglementaires ?
Ce blogue examine les caractéristiques de l’ensemble de données LS, les obstacles liés aux données LS et les conditions nécessaires pour faire progresser l’adoption de l’IA/GenIA dans l’industrie des sciences de la vie.
Données à travers la chaîne de valeur LS et ses contraintes
L’industrie des sciences de la vie est submergée de données, car elle dispose d’une abondance de types de données variés provenant de multiples sources à chaque étape de la chaîne de valeur pharmaceutique.
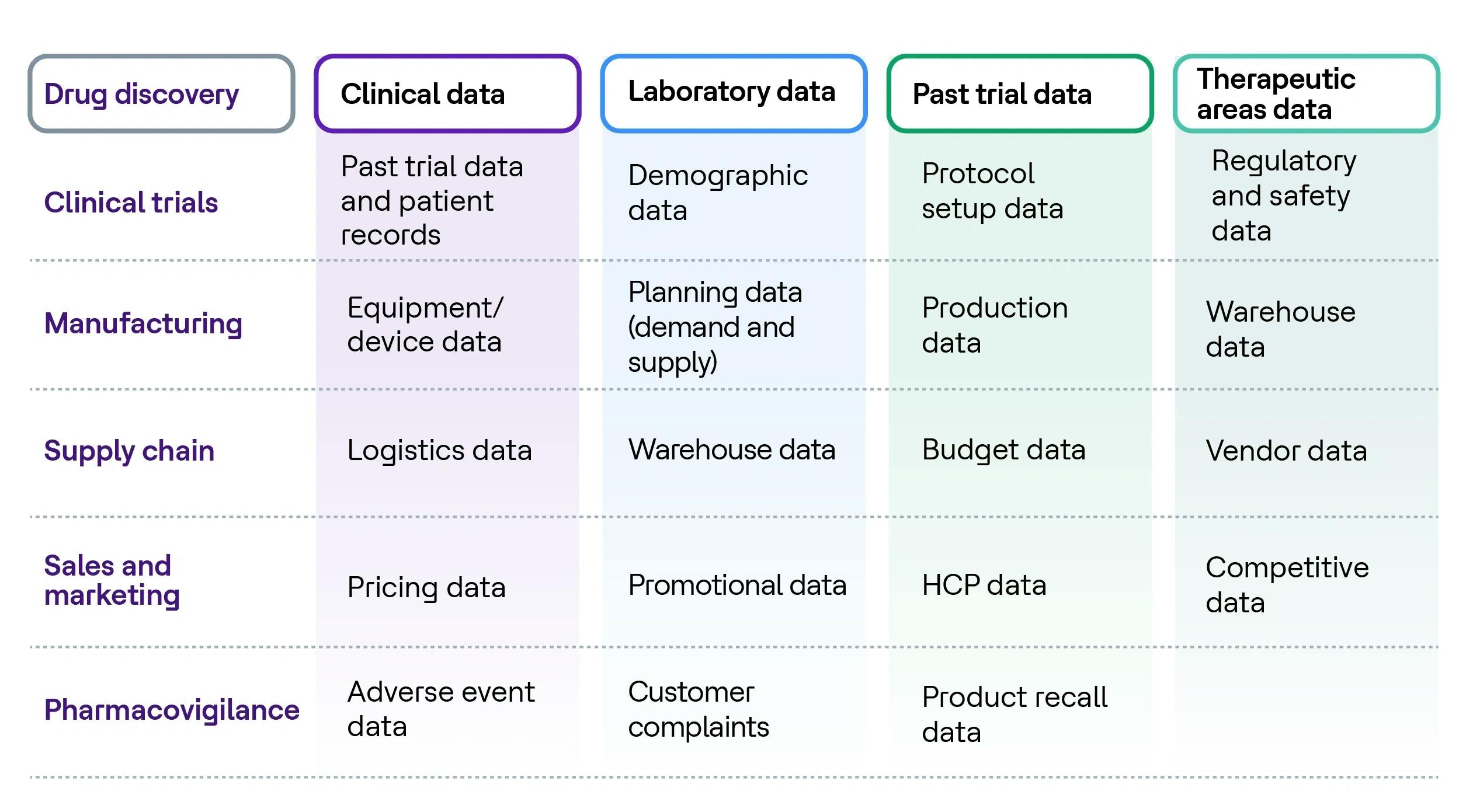
L’industrie LS n’a pas encore tiré les bénéfices de la donnée en raison d’un manque de données de haute qualité, d’interopérabilité des données et d’une gestion inefficace des données.
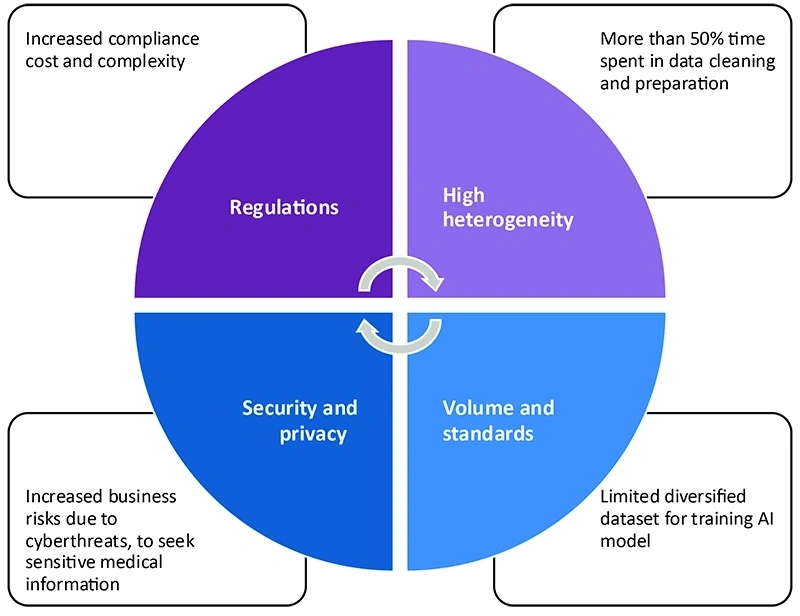
Défis liés aux données dans l’industrie des sciences de la vie
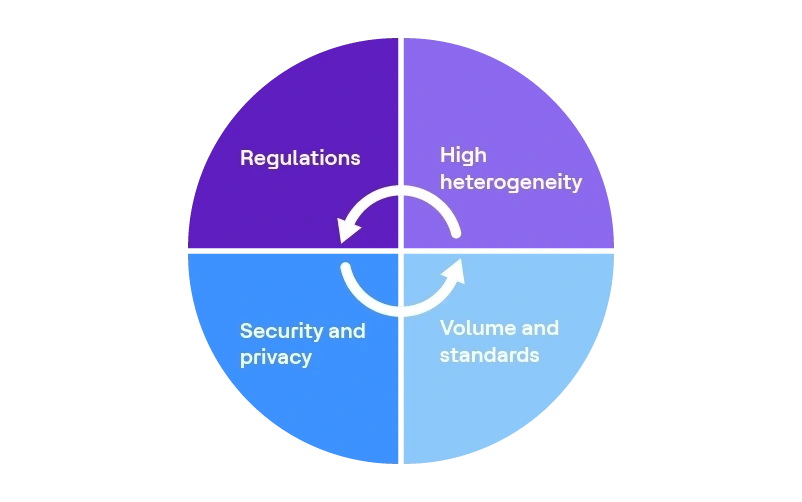
- Forte hétérogénéité
- Les données proviennent de multiples sources déconnectées et arrivent sous différentes formes et tailles. Par exemple, dans les données de R&D, il y a intégration de données provenant de sources déconnectées avec celles des patients, payeurs et professionnels de la santé par différents canaux.
- Volume et normes
- Les quantités massives de données proviennent de patients, de fournisseurs et de payeurs sous divers formats (texte/vidéo/images). De plus, les formats de données sont incohérents, non structurés et sans aucune norme de données.
- Disponibilité et accessibilité des données
- Bien que tout cela soit vrai, les données dans LS ne sont pas facilement disponibles et accessibles à tous en raison des exigences en matière de sécurité des données, de sécurité des patients et de réglementation.
- Réglementations
- Les organisations LS doivent se conformer à de nombreuses réglementations spécifiques à l’industrie dans des domaines tels que la collecte, le stockage, la transmission et le partage des données.
- Elles doivent également se conformer à des règlements régionaux tels que le RGPD européen (Règlement général sur la protection des données), la HIPAA (Health Insurance Portability and Accountability Act), la CCPA (California Consumer Privacy Act) et les BPF (Bonnes Pratiques).
L’impact des ensembles de données des sciences de la vie sur l’IA/GenIA
En raison de la nature inhérente des données LS, l’industrie des sciences de la vie éprouve des difficultés à unifier les silos de données et à élaborer des modèles de gouvernance des données pour les rendre compatibles avec l’entraînement des modèles d’IA.
De plus, un enjeu commun en IA est le biais dans les données (non propre aux LS seulement), c’est-à-dire la fiabilité de l’ensemble de données ou la source de vérité perçue. Pour s’assurer que les biais sont bien gérés, toute nouvelle technologie doit être « inclusive ». Cela n’est possible que si l’IA est entraînée à partir d’un échantillon exact et représentatif de l’ensemble de données diversifié.
- Si les ensembles de données contiennent des informations biaisées, le modèle affichera également ce même biais lors de la prise de décision.
- Le manque de données LS et de données biaisées aggrave les risques de façon exponentielle, notamment lorsque le modèle d’IA est intégré à des applications sensibles.
Stratégie de données robuste pour un développement d’IA digne de confiance – la voie à suivre
Une stratégie de données claire est nécessaire pour que la valeur réelle de l’IA devienne plus agile, rapide et efficace.
- Curation d’ensembles de données
- Utilisation de la bonne qualité et du bon volume de données pour entraîner l’IA sur un vaste ensemble qui peut ou non être disponible
- Nettoyer et harmoniser les données pour l’interopérabilité
- Réduction des biais dans les données
- Mise en place d’un design d’ensemble de données efficace
- Assurer l’intégrité des données (exactitude, exhaustivité et qualité tout au long de leur cycle de vie)
- Gestion des données de test
- Tests des données pour la qualité, l’adéquation à l’usage et la disponibilité au moment opportun
- Gouvernance des données
- Mise en œuvre d’un cadre de gouvernance des données
- Utilisation de garde-fous de sécurité pour le stockage et la transmission des données
- Gestion adéquate de l’accès aux données
- Conformité réglementaire
- Mise en place de mesures et contrôles clés, respect des directives du RGPD, des règlements et de la future Loi européenne sur l’IA (pour une IA responsable)
- Exploiter les normes définies existantes du NIST
- S’assurer que des politiques sont en place pour garantir des pratiques éthiques
- Mettre en œuvre des programmes de conformité robustes, des audits et des mesures proactives
- Documentation des données pour de futurs audits IA
Conclusion
Les dirigeants doivent adopter une démarche progressive pour devenir une organisation axée sur les données afin de révéler des informations à travers chaque élément de la chaîne de valeur, tels que :
- Collaboration efficace entre les leaders LS et ceux d’autres industries
- Création d’une stratégie IA claire, incluant les personnes, les processus et la technologie
- Partenariat avec des fournisseurs de services hyper-échelle pour tirer parti de l’IA pour la création de données (données synthétiques) et la preuve de concept (POC)
- Développer un processus de surveillance continue des données
La suite complète de services et de solutions d’HCLTech, incluant la validation, la réglementation, la cybersécurité, les données et les équipes spécialisées par domaine, est conçue pour aider les entreprises à accélérer la mise en œuvre de cas d’usage transformateurs d’IA/GenIA.


