

Ce blogue démontre comment les Agents Amazon Bedrock propulsés par Nova-Pro LLM peuvent accélérer la modernisation des systèmes de gestion des réclamations d'assurance, en passant des mainframes hérités à des plateformes infonuagiques comme Guidewire. La solution automatise les tâches d'analyse, de transformation et de migration des données, au bénéfice de divers rôles dans le cycle de développement logiciel. Bien que l'étude de cas porte sur la migration des réclamations d'assurance, cette solution sert de modèle à toute entreprise qui entreprend la modernisation de systèmes mainframe dans tous les secteurs d'activité.
Défi d'affaires
L'un des grands assureurs mondiaux a entrepris un programme stratégique de modernisation de la gestion des réclamations afin d'améliorer l'expérience client en migrant vers un nouveau système robuste de gestion des réclamations. Le programme de modernisation nécessitait l'extraction d'un grand volume de données de réclamations depuis un système de gestion des réclamations basé sur un mainframe, la transformation et la migration vers une base de données relationnelle Guidewire telle qu'Oracle ou MS SQL Server. Les données sources comprenaient les données des réclamations d'assurance avec des attributs tels que le numéro de compte assurance, le numéro de réclamation, les détails de la police, la date de l'incident, la description de l'incident et d'autres détails connexes.
Le client recherchait un accélérateur pour aider à réduire le temps de migration et améliorer la productivité de l'équipe du programme.
Approche de solution utilisant l’IA agentique
La solution a été conceptualisée dans le but d’accélérer le programme de migration en augmentant la productivité des différentes personnes œuvrant dans le programme tout au long du cycle de vie de développement logiciel (SDLC).
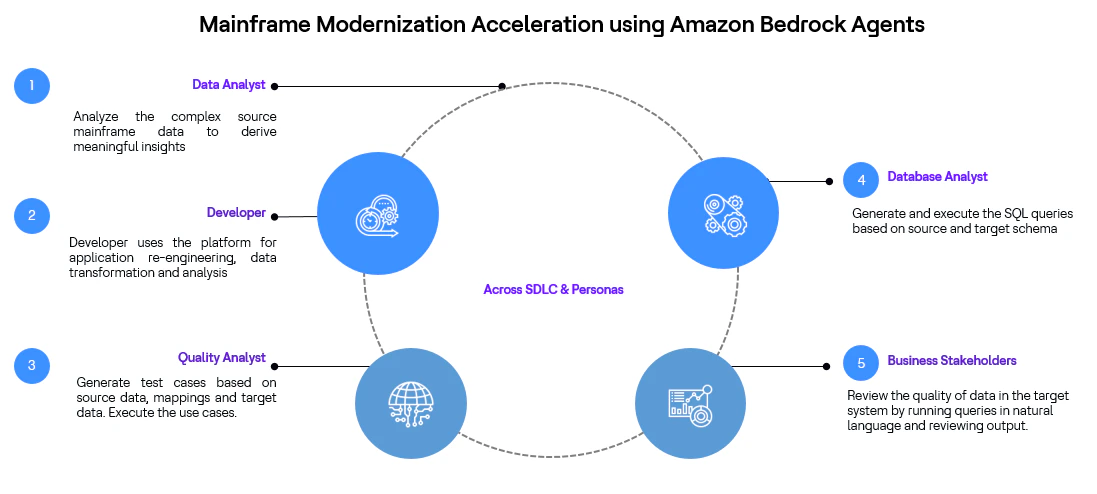
Voici quelques personas clés impliqués dans le programme et comment la solution vise à améliorer leur productivité.
Analyste de données – Utiliser l'accélérateur pour analyser les données sources complexes de gestion de police, générer les règles et la logique d’affaires à partir du code existant afin d’élaborer la documentation d’affaires requise.
Développeur – Utiliser la plateforme pour la réingénierie applicative, la transformation et l’analyse de données, générer des fichiers de correspondance source-cible, des scripts ETL ou la transformation de code de Cobol/JCL à Java ou tout autre langage de programmation.
Analyste en qualité – Générer des cas de test en fonction des données sources, des correspondances et des données cibles. Exécuter les cas d’utilisation et générer les résultats.
Parties prenantes d’affaires (UAT) – Examiner la qualité des données dans le système cible en exécutant des requêtes en langage naturel et en passant en revue les résultats.
Architecture de la solution sur AWS
La solution a été conçue et développée en fonction des objectifs principaux suivants.
- Capacité d’analyser et d’interroger un grand volume de données sources pour faciliter l’analyse
L’agent de transformation Bedrock, alimenté par Amazon Nova Pro LLM, a été utilisé pour analyser les données sources à l’aide d’une combinaison des fichiers extraits du système patrimonial, comprenant des détails tels que le numéro de compte, les détails de la réclamation, les détails de la police, etc., ainsi qu’un fichier de définition des données décrivant les attributs des données dans le fichier du système patrimonial source.

Fichier source d'exemple provenant des systèmes existants
| Numéro de champ | Description du champ | Définition du champ | Longueur du champ | Position de début | Position de fin | Positions de champ |
|---|---|---|---|---|---|---|
| 001 | Compte | Pic X(5) | 05 | 0001 | 0005 | 0001 - 0005 |
| 002 | Type d'enregistrement | Pic X(1) | 01 | 0006 | 0006 | 0006 - 0006 |
Fichier de définition de données d'exemple fournissant des détails sur le fichier source
- Générer la cartographie de transformation, les scripts ETL et la transformation du code
La cartographie de transformation et les scripts ETL ont été générés afin de transformer les données sources vers le schéma cible du système Guidewire à l'aide de l'agent de transformation Bedrock. Une fois que les données du fichier source, le fichier de définition des données et le schéma de la base de données cible ont été fournis à l'agent, celui-ci est en mesure de générer la cartographie de transformation et les scripts ETL.

Cartographie de transformation générée par l’agent
L’agent peut également être utilisé pour la transformation de code de Cobol, JCL vers Java ou tout autre langage de programmation.
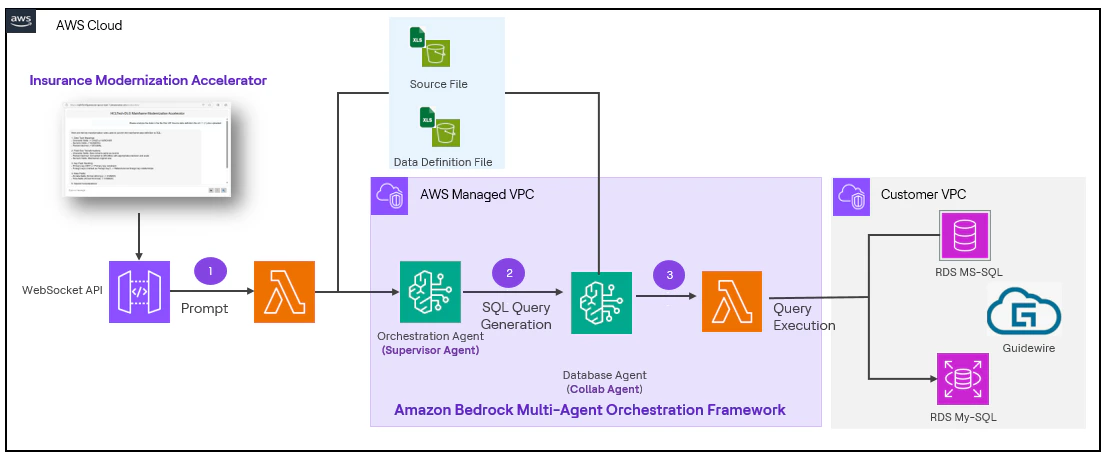
- Génération de requêtes SQL pour l’insertion de données dans le système de base de données relationnelle backend
L’agent a pu générer des requêtes SQL pour insérer les données dans le schéma cible — base de données relationnelle — sans intervention manuelle en utilisant l’agent de base de données. L’agent peut être utilisé pour générer des scripts ETL qui peuvent servir lors de la migration, si le volume de données est élevé et que le coût augmente au lieu d’insérer les données directement.
Aperçu des composants de la solution
La solution globale a été construite à l'aide du cadre multi-agents Amazon Bedrock, Amazon Nova Pro, AWS Lambda, API WebSocket, S3, UI React et base de données (RDS).
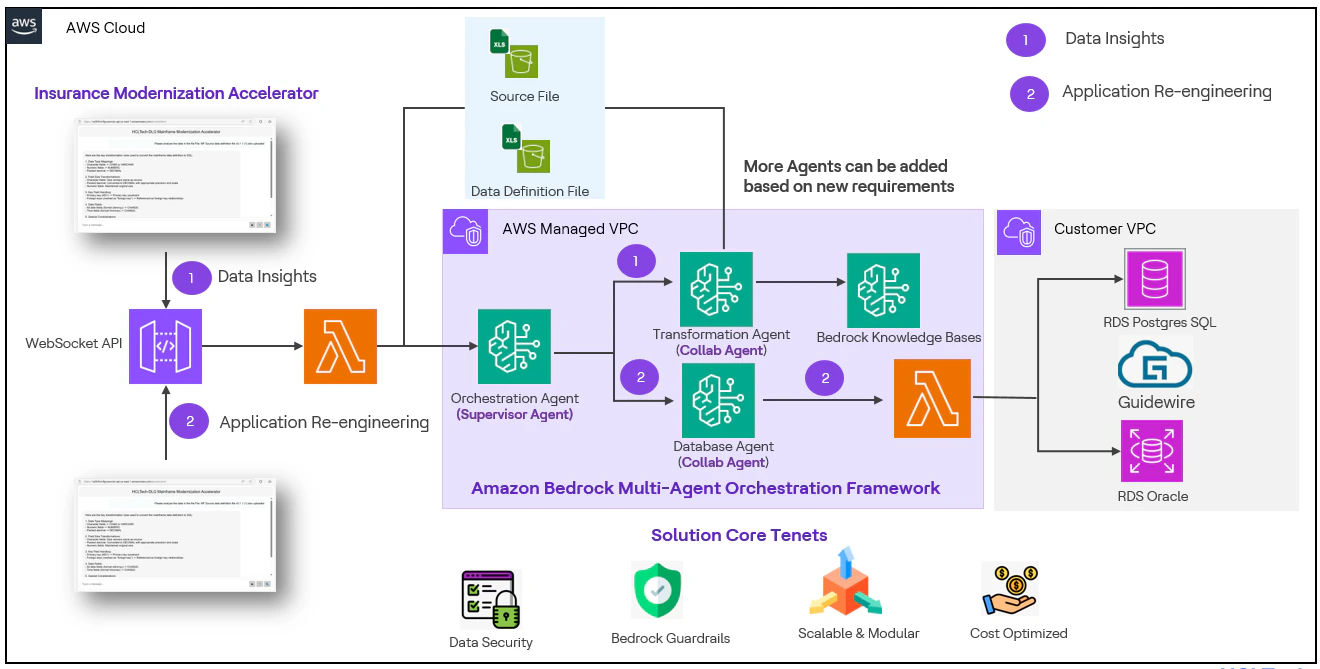
Agents Amazon Bedrock – La solution utilise le cadre multi-agents Amazon Bedrock et comprend trois agents.
- L’agent Orchestrateur (Superviseur) se concentre sur l’acheminement et la collaboration entre différents agents.
- L’agent de transformation (collaborateur) analyse les données pour en extraire des informations et génère la logique de transformation : mappage, scripts ETL, transformation de code.
- L’agent de base de données (collaborateur) génère des requêtes SQL pour insérer les données dans une base de données relationnelle.
Grand modèle de langage – Les Agents utilisent Amazon Nova Pro.
Interface utilisateur interactive React – L’interface utilisateur interactive React offre une interface de clavardage hébergée sur ECS Fargate.
API Websocket AWS – Sert d’interface de clavardage persistante pour acheminer la communication entre l’utilisateur et les Bedrock Agents qui sont déployés sur la passerelle API.
AWS Lambda – L’entrée de l’utilisateur reçue via l’API web socket est transmise aux agents en appelant l’API invoke Agent.
Sécurité – Voici les attributs pris en compte pour élaborer une solution robuste et sécuritaire.
| Domaine de sécurité | Stratégie de mise en œuvre et services AWS |
|---|---|
| IA responsable – Toxicité, rédaction des IPI, hallucinations | AWS Bedrock Guardrails pour le contrôle de la toxicité, la rédaction des IPI et l’ancrage contextuel afin de détecter et atténuer les hallucinations |
| Données au repos | AWS Key Management Service (KMS) pour le chiffrement des données dans Amazon S3 et les bases de données RDS. |
| Données en transit | AWS PrivateLink avec points de terminaison d’interface VPC pour une communication sécurisée entre services AWS; chiffrement TLS pour toutes les interactions client-service. |
| Authentification et autorisation | Amazon Cognito (ou solution d’entreprise similaire) pour la gestion sécuritaire des identités des utilisateurs et les flux d’authentification; IAM pour un contrôle précis des permissions avec accès basé sur les rôles |
| Protection DDoS | Défense multicouche avec AWS Shield pour la protection au niveau réseau (L3/L4) et AWS WAF pour le filtrage de la couche applicative (L7) contre les vecteurs d’attaque sophistiqués |
Scénarios d’utilisation
Voici quelques scénarios illustrant le fonctionnement de la solution :
Persona 1 – Analyste de données
- Le fichier mainframe source est extrait et téléversé dans un dossier source dans le compartiment S3.
- Le fichier de définition des données définit les noms d'attributs dans le fichier mainframe source, comme l'identifiant client, le numéro de police, la date de police, etc.
- Supposons maintenant qu'un analyste de données doive analyser le fichier mainframe source. Il peut soit téléverser le fichier source et le fichier de définition des données à l'aide d'une interface utilisateur développée avec React, soit les téléverser dans le compartiment S3.
- Ensuite, l'analyste fournit l'invite avec le fichier source. Ces données sont envoyées à l'API web socket, qui transmet les données à la fonction lambda comme un événement.
- La fonction lambda utilise l'API invoke Agent pour envoyer l'entrée à l'Agent orchestrateur.
- L'agent orchestrateur achemine la demande à l'Agent de transformation, qui utilise le LLM sous-jacent pour effectuer l'analyse et générer des insights selon l'invite et les données sources.
- Une approche similaire peut être utilisée pour l'extraction de règles d'affaires à partir du code patrimonial existant disponible.
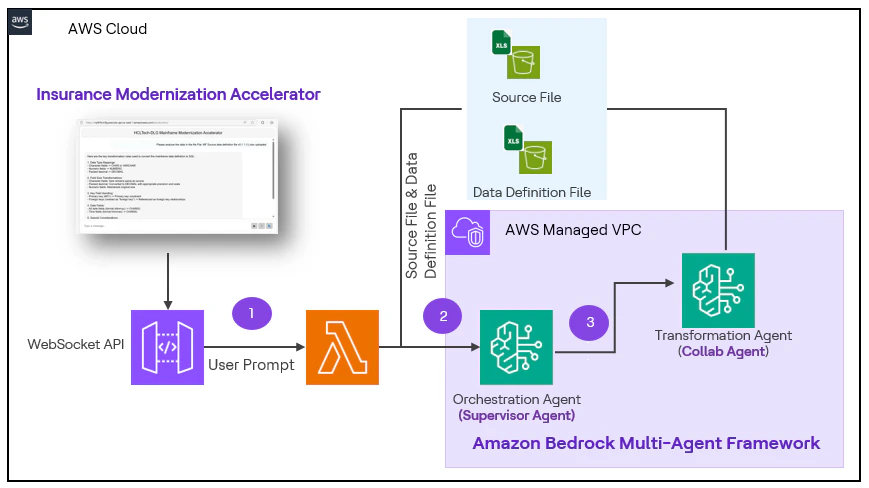
Persona 2 - Développeur
- La tâche principale du développeur est d'utiliser le fichier source du mainframe comme entrée, de transformer les données – fichier de correspondance, scripts ETL et d'insérer les données dans la BD en arrière-plan.
- Le développeur téléverse le fichier source, le fichier de définition de données et la requête via l'interface utilisateur.
- Cette entrée est transmise à l'API web socket puis à AWS Lambda qui déclenche l'appel à l'API de l’agent Bedrock.
- Une fois les entrées reçues par l’agent d’orchestration, il achemine la demande vers l’agent de transformation qui génère la logique de correspondance selon le schéma source et cible, puis retourne la réponse à l’utilisateur.
- Si le développeur demande l’insertion des données transformées, l’agent de base de données génère les requêtes SQL et utilise le groupe d’actions lié pour insérer les données dans la base de données RDS.
- En suivant un flux similaire, la solution peut être utilisée pour la transformation de code.
Avantages de la solution et améliorations futures
Comparativement aux approches traditionnelles de migration pour la modernisation des grands systèmes centraux, l’accélérateur de solution peut réduire les délais de migration jusqu’à 30 %.
L’accélérateur de solution est en cours d’amélioration afin de renforcer la compréhension contextuelle de la solution Agentic et de générer des résultats personnalisés en fonction de variables d’environnement propres au client, telles que la documentation disponible, le code existant et d’autres paramètres similaires. D’autres améliorations incluent l’intégration avec des modèles d’apprentissage automatique pour la réconciliation automatisée entre les systèmes source et cible, ainsi que l’ajout d’autres composants de modernisation des grands systèmes centraux comme la migration de fichiers VSAM, et ainsi de suite.
Défis et enjeux
Lors de la mise en œuvre de la solution, dans le cas de grandes quantités de données de fichiers source, l’API Websocket d’AWS peut atteindre la limite maximale de taille de fichier, ce qui peut être atténué en accédant aux données via S3.
Dans le cas d’un très gros volume de données à migrer, le coût de génération de requête SQL et d’insertion de données dans le système Guidewire peut être prohibitif. Dans ces situations, une partie de la tâche peut être gérée à l’aide d’ETL. L’agent peut générer ces scripts.
Conclusion
La solution démontre comment nous pouvons bâtir une plateforme complète afin d’accélérer la migration de la gestion des polices à l’aide des agents Amazon Bedrock et de Nova-Pro LLM. Cette solution peut être encore personnalisée pour améliorer l’expérience client dans différents cas d’utilisation de migration dans l’industrie de l’assurance.
Pour plus d’informations détaillées, une démonstration ou pour mettre en œuvre cette solution, veuillez communiquer avec notre équipe d’experts : awsecosystembu@hcltech.com



