

Introduction
À mesure que les entreprises passent de l'étape d'exploration des applications GenIA à des applications évolutives de niveau production, elles sont confrontées à plusieurs défis. L’un des principaux défis est le coût et le temps de réponse des grands modèles de langage (LLM), en particulier lorsque plusieurs utilisateurs simultanés interagissent avec l’application GenIA.
Comme tout autre mécanisme de mise en cache, le LLM peut aider à répondre à ces préoccupations concernant les applications GenIA. En introduisant et en mettant en œuvre une couche de mise en cache LLM lors des échanges de requêtes/réponses, la performance de l’application peut être considérablement améliorée. Les accès réussis au cache évitent le traitement basé sur le LLM, et les résultats sont récupérés directement des entrées persistantes du cache, ce qui se traduit par une amélioration des performances.
Ce blogue expliquera en détail le fonctionnement de la mise en cache des LLM et explorera la conception d’applications GenIA basées sur la génération avec récupération augmentée (RAG) avec et sans mise en cache LLM. Il abordera également les considérations de conception uniques et les défis liés à la mise en cache des réponses du modèle linguistique, explorera différentes approches de mise en cache et fournira une étude comparative de la performance des applications avec la mise en cache LLM.
Cache LLM
En informatique, un cache est un composant matériel ou logiciel qui stocke des données afin de permettre une récupération plus rapide pour les demandes futures. Les données stockées peuvent résulter d’un calcul précédent ou être une copie d’informations se trouvant ailleurs. Un accès réussi au cache se produit lorsque les données demandées se trouvent dans le cache, tandis qu’un défaut de cache signifie que les données ne sont pas disponibles. Les accès au cache sont servis en lisant les données directement à partir du cache, ce qui est plus rapide que de recalculer un résultat ou de le récupérer d’un stockage de données plus lent. Par conséquent, plus le nombre de requêtes pouvant être satisfaites à partir du cache est élevé, plus la performance globale du système est rapide.
Le concept d’un cache LLM suit le même principe de conception fondamental. Dans le contexte des applications GenIA propulsées par LLM, les paires requête-réponse servent d’entrées principales pour la mise en œuvre du cache LLM. Le cache LLM est interrogé chaque fois qu’une demande future est faite pour trouver une entrée similaire. Si une réponse correspondante est trouvée dans le cache, elle est directement retournée à l’utilisateur, ce qui constitue un accès réussi au cache LLM. À l’inverse, si aucune entrée correspondante n’est trouvée dans le cache LLM, l’appel réel au LLM génère la réponse, constituant un défaut de cache LLM.
Considérations de conception du cache LLM
Entrées de données du cache LLM — La paire requête/réponse générée par les appels LLM est stockée de façon persistante pour servir d’entrées au cache. Les requêtes/questions seraient également stockées sous forme d’incorporations vectorielles afin de permettre une recherche sémantique.
Graine du cache LLM — Le mécanisme/processus/planification pour maintenir la persistance du magasin de cache. Idéalement, chaque accès réussi au LLM serait stocké dans le cache afin de permettre le service du cache pour une requête similaire ultérieure.
Purge du cache LLM — Les entrées du cache peuvent devenir obsolètes en raison de changements dans les sources de connaissances respectives. Les entrées du cache doivent être rafraîchies selon un calendrier ou par déclenchement dynamique chaque fois que les sources de données sous-jacentes sont mises à jour afin d’éviter des réponses non pertinentes ou obsolètes.
Mise en œuvre basée sur RAG avec cache LLM
Dans la conception d’applications GenIA basée sur RAG, les requêtes des utilisateurs reçoivent une réponse à partir des sources de connaissances vectorisées définies de l’organisation. Voici comment l’intégration du cache LLM dans l'application basée sur RAG peut améliorer la performance globale :
- L’utilisateur interagit avec l’application et soumet une requête spécifique
- La requête de l’utilisateur est convertie en incorporation vectorielle, et des techniques de recherche sémantique sont utilisées pour trouver une correspondance pertinente dans les entrées mises en cache
- La recherche sémantique est effectuée sur les entrées du cache afin de trouver des réponses correspondantes :
- Si une correspondance rapprochée est trouvée selon le seuil de recherche de similarité défini, elle est considérée comme un accès réussi au cache et la réponse correspondante est retenue à partir des entrées mises en cache correspondantes
- Si aucune correspondance rapprochée n’est trouvée selon le seuil de recherche de similarité défini, il est considéré comme un défaut de cache et la demande est acheminée pour être récupérée à partir de la couche RAG/LLM sous-jacente
- En cas d'accès réussi au cache, la réponse correspondante est renvoyée à l'utilisateur (aucun appel LLM réel n'est nécessaire pour une réponse d'accès au cache)
- En cas de défaut de cache, lorsqu’aucune donnée proche mise en cache n’est disponible, la requête de l’utilisateur est acheminée vers le magasin de connaissances réel pour une correspondance de similarité
- Les K données les plus pertinentes sont extraites du magasin de connaissances et, avec la requête originale de l'utilisateur, sont envoyées au LLM pour générer la réponse
- La réponse finale générée par le LLM est envoyée à l'utilisateur, et simultanément, le cache est mis à jour avec cette réponse afin de faciliter de futurs accès réussis au cache pour des requêtes pertinentes
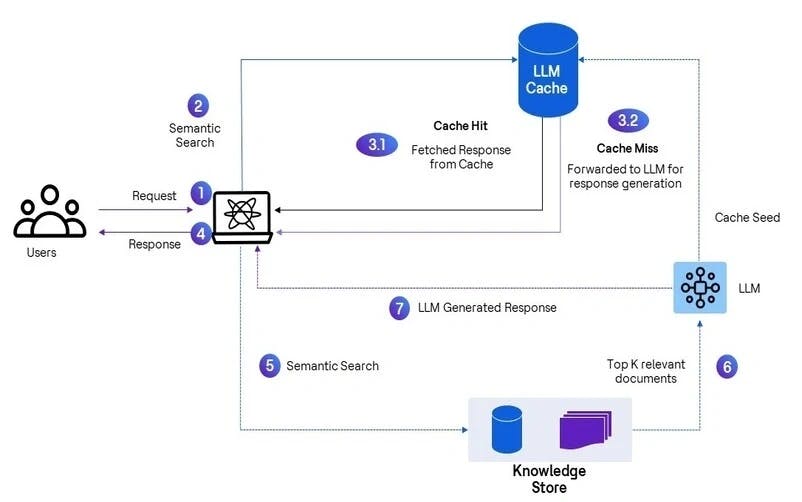
Figure : Mise en œuvre RAG avec cache LLM
Comme nous l’avons vu, les accès réussis au cache LLM évitent les appels réels au LLM. Ci-dessous, la façon dont les pourcentages d’accès au cache influencent la performance globale de la génération de réponses et le coût des LLM.
Évaluation de la performance
Dans cette expérience, nous avons utilisé ChromaDB comme magasin de connaissances (base de données vectorielle) et le modèle Claude v2 d’Anthropic, accessible via Amazon Bedrock, comme grand modèle de langage (LLM) pour la génération de réponses. Nous avons mené quatre itérations, chacune composée de dix requêtes, avec des pourcentages variables d’accès réussi au cache LLM. Les observations de performance sont les suivantes :
En faisant varier le pourcentage d’accès réussi au cache LLM, nous avons pu évaluer l’impact des réponses mises en cache sur la performance globale du système. Les observations de performance à travers les quatre itérations ont révélé des tendances et des motifs de performance intéressants. Le temps de réponse moyen pour dix requêtes sans cache est d’environ 2,8 secondes, ce qui diminue linéairement avec des ratios d’accès au cache plus élevés.
Facteur de durabilité
L’inquiétude grandit quant à la consommation significative d’énergie et d’eau associée à l’exploitation des grands modèles de langage (LLM), souvent appelés « monstres géants assoiffés » en raison de leurs importantes demandes en ressources. Ce problème représente un défi crucial alors que l’adoption et l’intégration des LLM ne cessent d’augmenter dans divers secteurs et applications.
La mise en œuvre d’un cache LLM est importante pour atténuer ce facteur de risque et tendre vers une utilisation plus durable des LLM. Grâce aux mécanismes de mise en cache, on peut minimiser la récupération et le traitement répétitifs de l'information, ce qui réduit l’empreinte énergétique et hydrique globale des systèmes propulsés par LLM.
Conclusion
L’implémentation du cache LLM dans les applications IA générative peut considérablement améliorer la performance et réduire les coûts en évitant les coûteux appels LLM pour des requêtes répétées. Le cache LLM peut extraire rapidement les réponses pertinentes en stockant les paires requête-réponse et leurs incorporations vectorielles, ce qui se traduit par des temps de réponse plus rapides et un moindre coût computationnel. Les considérations de conception entourant les entrées des données du cache, la maturation et la purge sont essentielles pour garantir que le cache LLM reste à jour et efficace. L’architecture basée sur RAG avec cache LLM montre comment le cache peut être intégré de façon transparente, offrant un gain tangible de performance.
À mesure que les organisations mettent à l’échelle leurs applications GenIA, exploiter le cache LLM devient une stratégie essentielle pour libérer tout le potentiel des grands modèles de langage tout en faisant face aux défis de coût et de temps de réponse.
Pour une compréhension détaillée, une démonstration ou une mise en œuvre de cette solution, veuillez nous contacter : awsecosystembu@hcltech.com.
Références :


