
Visual perception enables the machines to possess the ability to perceive and derive meaningful information from images, videos and other optical inputs. This is aptly described in Figure 1. The information is useful for robots and autonomous systems to manipulate and navigate in their environment and other relative locations. It describes the shape and size of the objects and their relative locations for manipulation. It can also provide knowledge about the nature of obstacles and terrain characteristics for navigation systems.
Primarily, the camera is the source of images for visual perception. The images acquired from the camera must be pre-processed to ensure quality, i.e., without any noise and distortions. After pre-processing, the object present in the images can be identified using any machine learning-based computer vision techniques. However, the objects are described in reference to the image in terms of pixels. Hence, there is a need for techniques that transform the image/pixel coordinates into 3D world so that the knowledge of the object can be perceived for further usage.
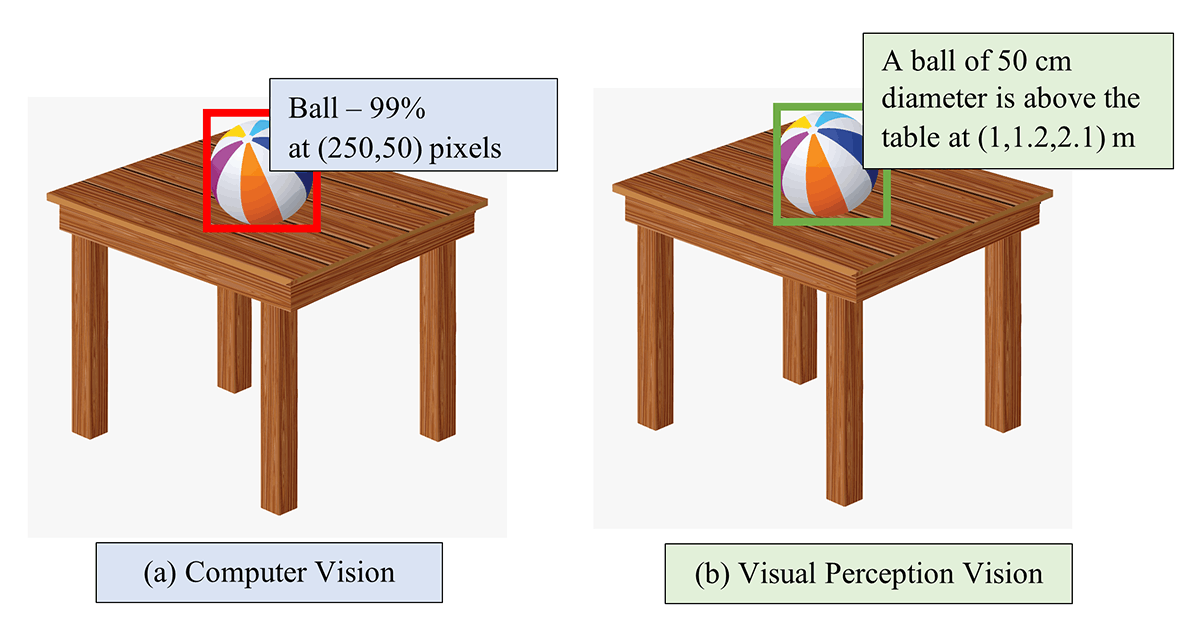
Figure 1. Comparison of computer vision and visual perception
The following are the problems that must be addressed to enable visual perception for cameras:
- Manual calibration – Manual interventions are needed to derive a scale/conversion factor that can convert the pixel information to the 3D world coordinates. It depends on several factors such as the type of camera, focal length, camera location, etc.
- Camera distortion – The design constraints of the camera, like focal length and type of lens used, can distort the quality of images. The barrel effect and pincushion effect (Refer Figure 2) are some of the widely encountered camera distortions that can hinder visual perception. It makes the non-uniform scale for converting pixels to 3D world coordinates.
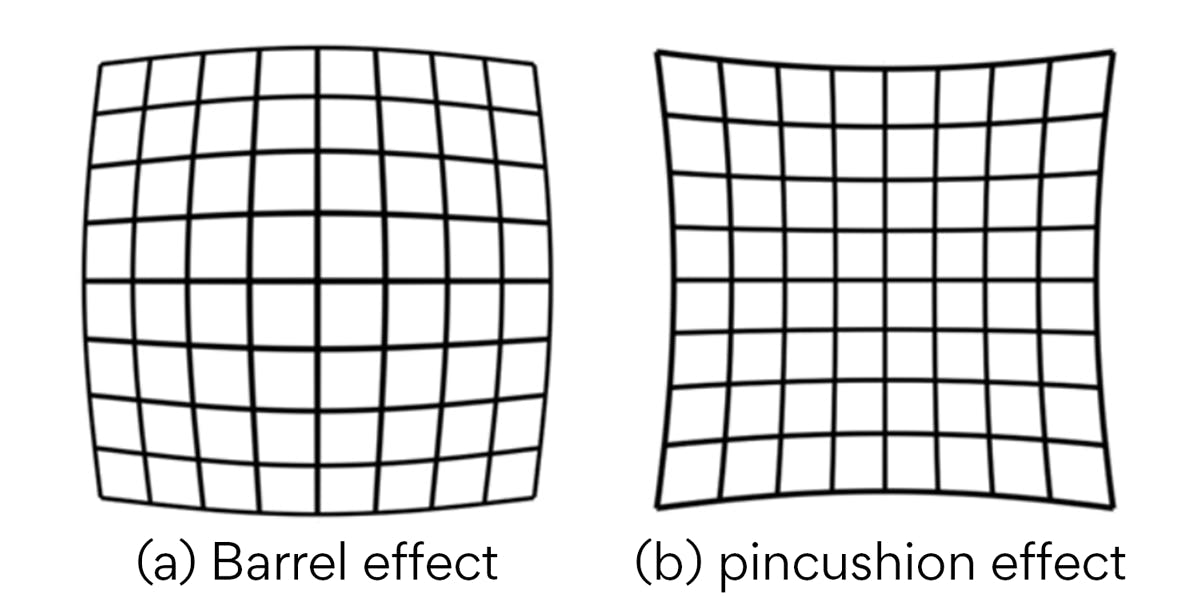
Figure 2. Camera lens distortion effect
- Camera misalignment – The transformation scale is derived under the assumption that the camera position is well-defined. The scale becomes erroneous when the camera encounters misalignments.
- On-robot/dynamic camera – The camera mounted on the robot arm is often termed an on-robot camera, which is gaining potential applications in recent times. It makes the camera location dynamic and demands dynamic scaling factors.
The automatic camera calibration technique emerges as a solution to address these problems and enable the visual perception of the camera. It predominantly involves reversing the conversion that happens inside the camera to convert the world objects into pixels. Thus, creating an inverse model of a camera to convert the pixels into world objects, as in Figure 3. It involves the detection of camera intrinsic and extrinsic parameters as described below,
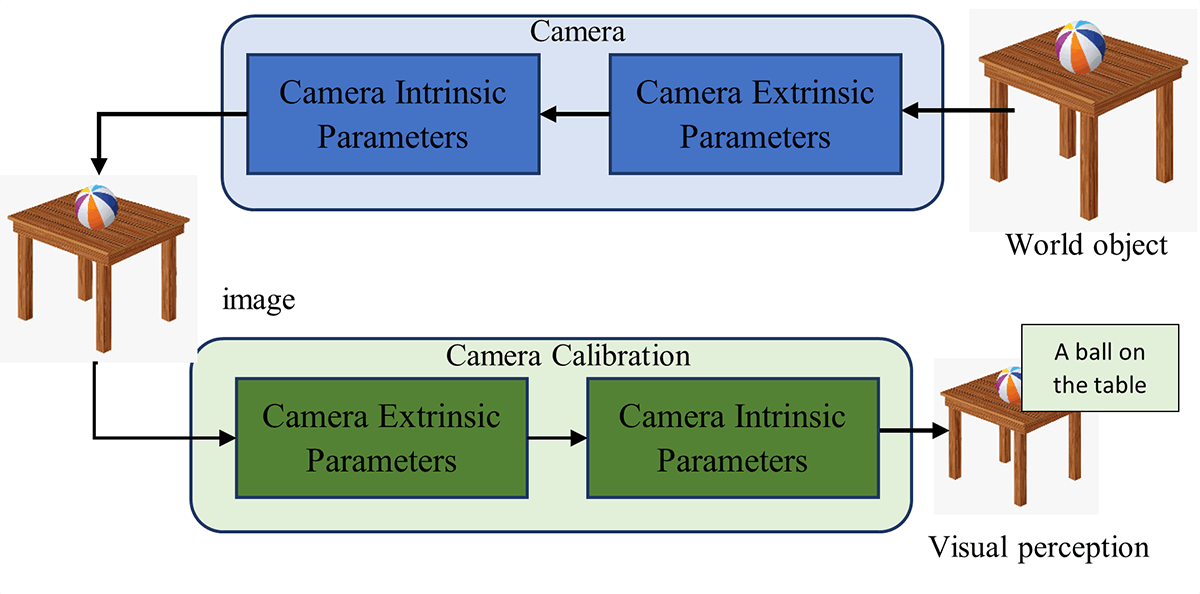
Figure 3. Camera calibration for visual perception
- Camera extrinsic parameters – The camera extrinsic parameters are expressed in matrix form, which acts as a transformation matrix that transforms the world coordinate system into a camera coordinate system. It is a combination of the rotation and translation matrix. It depends on the location and orientation of the camera
- Camera intrinsic parameters – The camera intrinsic parameters described as a matrix are used to transform the camera coordinate system into a pixel coordinate system. It depends on internal factors such as focal length, the field of view, aperture, etc.

Camera calibration is achieved by using reference patterns like a chessboard pattern, AR tags and QR codes, as illustrated in Figure 4. The distortions encountered by the image of the reference pattern are used to get camera parameters. Initially, the intrinsic matrix is determined, and the extrinsic matrix is found later, which helps to remove the distortions and be used in finding the object locations. It is recommended to use multiple images to increase the accuracy, and it is better to keep the reference pattern on the same plane where our actual object of interest is present.
Several images of the reference pattern at different positions and orientations are acquired, which are used in calculating the intrinsic parameters. The rotation and translation of the camera can also be determined to be used to generate the extrinsic parameters. After this, some real-world coordinates with their corresponding image coordinates are used to calculate the scaling factor (S, see in the equation). The scaling factor is used to determine the object dimensions independent of the distance between the camera and the object. Thus, the intrinsic and extrinsic matrices and the scaling factor is used to convert the camera pixel coordinates to the world coordinates. The calculated world coordinates can be sent to different types of robots, such as pick and place robots and inspection robots for manipulation.
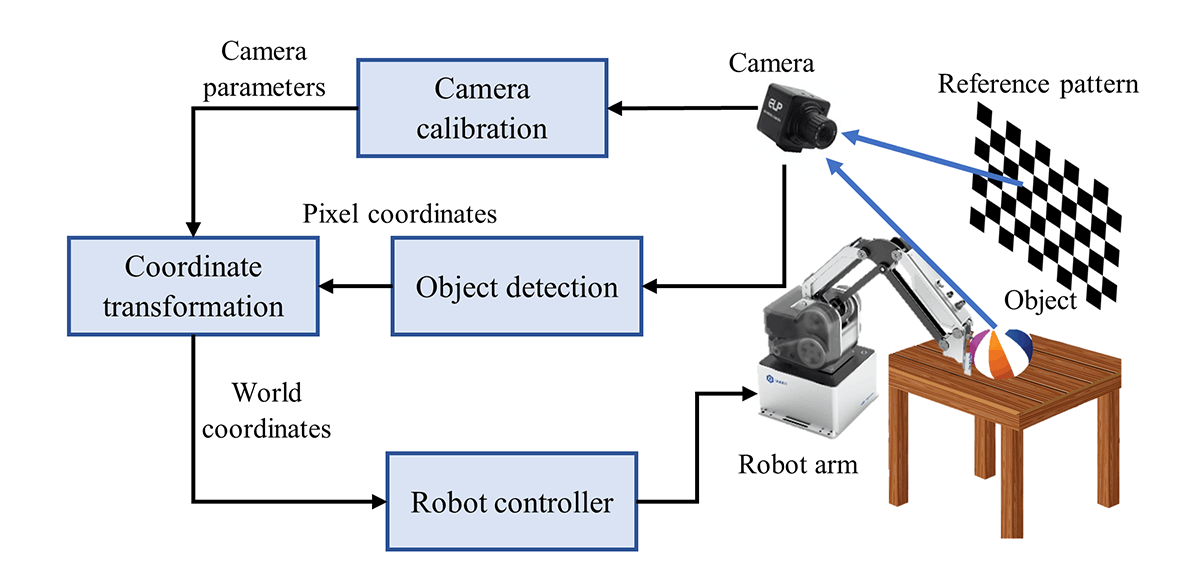
Figure 4. Application of visual perception using camera calibration
Applications
- Pick and place robot
- Material handling systems
- Assembly and quality inspection
- Dimension and counting of objects
- Automated device testing applications
Key benefits
- Eliminates manual interventions and significantly reduces the deployment time via automatic calibration
- Lowers possibilities of human error
- Reduces the manual effort involved in determining the camera calibration
- Compensates for lens distortion (Fisheye/Barrel, pincushion distortion) and camera misalignments
- Enhances images that can minimize error in OCR and other applications
Overheads
- The quality of the reference image and the number of images impact the quality of the estimated camera parameters
- Dynamic change in camera positions needs intense computational capability to determine the change in camera parameters
Humans can perceive an object in an image and in the real world with little or no effort, but machines depend on learning pattern-matching algorithms to perceive an object. So, any distortions or noise in the images will cause a significant impact if not corrected properly. Camera calibration emerges as a potential solution to this problem, which can understand the distortions encountered by the camera and takes corrective actions. This enables the machines to have the visual perception that can truly understand the world’s objects through camera images. Thus, this knowledge can provide autonomous systems like robots to seamlessly manipulate or navigate in an unknown environment.

